解释一个使用标准化特征的模型
对于许多机器学习流程来说,标准化特征是一个常见的预处理步骤。在解释一个使用标准化特征的模型时,我们通常希望使用原始输入特征(而不是它们的标准化版本)来获得解释。本笔记展示了如何利用“应用于模型输入的任何单变量变换不影响模型的 Shapley 值”这一特性来实现这一点(请注意,像 PCA 分解这样的多变量变换确实会改变 Shapley 值,因此这个技巧不适用于那些情况)。
构建一个使用标准化特征的线性模型
[1]:
import nbtest
import sklearn
import shap
# get standardized data
X, y = shap.datasets.california()
scaler = sklearn.preprocessing.StandardScaler().set_output(transform="pandas")
X_std = scaler.fit_transform(X)
# train the linear model
model = sklearn.linear_model.LinearRegression().fit(X_std, y)
# explain the model's predictions using SHAP
explainer = shap.LinearExplainer(model, X_std)
shap_values = explainer(X_std)
# visualize the model's dependence on the first feature
shap.plots.scatter(shap_values[:, 0])
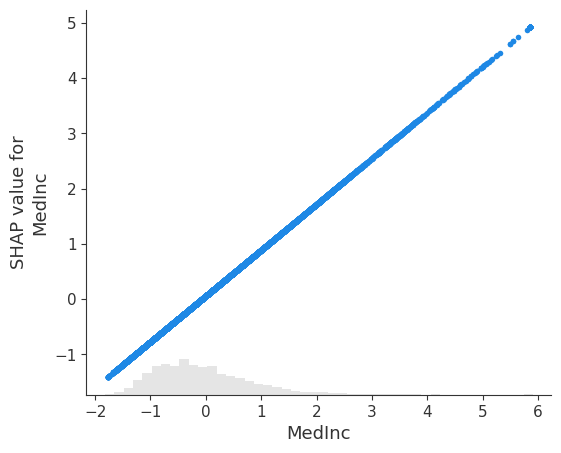
[2]:
# We test the additivity of the SHAP values against the model's predictions.
# This test only runs in the continuous integration pipeline
# in order to run manually uncomment the following two lines:
# import os
# os.environ['NBTEST_RUN_ASSERTS'] = '1'
predicted_value = model.predict(X_std)
nbtest.assert_allclose((shap_values.base_values + shap_values.values.sum(1)), predicted_value)
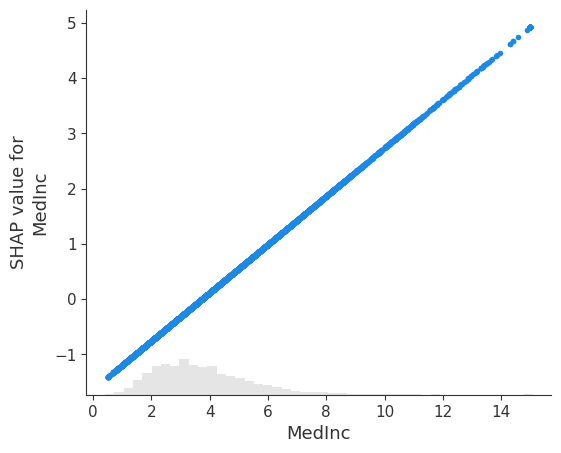
将解释转换到原始特征空间
[3]:
# we convert back to the original data
# (note we can do this because X_std is a set of univariate transformations of X)
shap_values.data = X.values
# visualize the model's dependence on the first feature again, now in the new original feature space
shap.plots.scatter(shap_values[:, 0])
对更有帮助的示例有什么想法吗?我们鼓励您通过拉取请求(Pull Request)来为本文档笔记本添砖加瓦!