正面与负面情感分类
在这里,我们演示如何解释电影评论的情感分类模型。正面与负面情感
[47]:
import datasets
import numpy as np
import transformers
import shap
加载 IMDB 电影评论数据集
[2]:
dataset = datasets.load_dataset("imdb", split="test")
# shorten the strings to fit into the pipeline model
short_data = [v[:500] for v in dataset["text"][:20]]
Reusing dataset imdb (/home/slundberg/.cache/huggingface/datasets/imdb/plain_text/1.0.0/90099cb476936b753383ba2ae6ab2eae419b2e87f71cd5189cb9c8e5814d12a3)
加载并运行情感分析管道
[3]:
classifier = transformers.pipeline("sentiment-analysis", return_all_scores=True)
classifier(short_data[:2])
[3]:
[[{'label': 'NEGATIVE', 'score': 0.0012035118415951729},
{'label': 'POSITIVE', 'score': 0.9987965226173401}],
[{'label': 'NEGATIVE', 'score': 0.002218781039118767},
{'label': 'POSITIVE', 'score': 0.9977812170982361}]]
解释情感分析管道
[4]:
# define the explainer
explainer = shap.Explainer(classifier)
[5]:
# explain the predictions of the pipeline on the first two samples
shap_values = explainer(short_data[:2])
[6]:
shap.plots.text(shap_values[:, :, "POSITIVE"])
第 0 个实例
昨晚在几个朋友的劝说下,我去看这部电影了。我承认我不太想看,因为就我所知,艾什顿·库彻只会演喜剧。
我错了。库彻把杰克·费舍尔这个角色演得很好,凯文·科斯特纳把本·兰德尔演得非常专业。
一部好电影的标志是它可以玩弄我们的情绪。这部电影正是这样做的。
整个剧院(全部售罄)在期间充满了笑声
第 1 个实例
演员转导演比尔·帕克斯顿继他备受瞩目的处女作——哥特式恐怖片《脆弱》之后,又推出了这部家庭友好型体育剧,讲述了 1913 年美国的故事。
公开赛,一位年轻的美国球童从卑微的背景中崛起,与他的英国对手比赛
偶像,这场比赛被称为“有史以来最伟大的比赛”。
”我不是高尔夫球迷,这些勉强获胜的弱势体育电影随处可见(最近的成功案例是《奇迹》和《灰姑娘男人》),
但不知何故,这部电影令人着迷
手动包装管道
SHAP 要求分类器输出张量,并且解释在加性空间中效果最佳,因此我们将概率转换为 logits 值(信息值而不是概率)。
创建 TransformersPipeline 包装器
[7]:
pmodel = shap.models.TransformersPipeline(classifier, rescale_to_logits=False)
[8]:
pmodel(short_data[:2])
[8]:
array([[0.00120351, 0.99879652],
[0.00221878, 0.99778122]])
[9]:
pmodel = shap.models.TransformersPipeline(classifier, rescale_to_logits=True)
pmodel(short_data[:2])
[9]:
array([[-6.72130722, 6.72133589],
[-6.10857607, 6.10857523]])
[13]:
explainer2 = shap.Explainer(pmodel)
shap_values2 = explainer2(short_data[:2])
shap.plots.text(shap_values2[:, :, 1])
第 0 个实例
昨晚在几个朋友的劝说下,我去看这部电影了。我承认我不太想看,因为就我所知,艾什顿·库彻只会演喜剧。
我错了。库彻把杰克·费舍尔这个角色演得很好,凯文·科斯特纳把本·兰德尔演得非常专业。
一部好电影的标志是它可以玩弄我们的情绪。这部电影正是这样做的。
整个剧院(全部售罄)在期间充满了笑声
第 1 个实例
演员转导演比尔·帕克斯顿继他备受瞩目的处女作——哥特式恐怖片《脆弱》之后,又推出了这部家庭友好型体育剧,讲述了 1913 年美国的故事。
公开赛,一位年轻的美国球童从卑微的背景中崛起,与他的英国对手比赛
偶像,这场比赛被称为“有史以来最伟大的比赛”。
”我不是高尔夫球迷,这些勉强获胜的弱势体育电影随处可见(最近的成功案例是《奇迹》和《灰姑娘男人》),
但不知何故,这部电影令人着迷
将分词器作为掩码器对象传递
[15]:
explainer2 = shap.Explainer(pmodel, classifier.tokenizer)
shap_values2 = explainer2(short_data[:2])
shap.plots.text(shap_values2[:, :, 1])
第 0 个实例
昨晚在几个朋友的劝说下,我去看这部电影了。我承认我不太想看,因为就我所知,艾什顿·库彻只会演喜剧。
我错了。库彻把杰克·费舍尔这个角色演得很好,凯文·科斯特纳把本·兰德尔演得非常专业。
一部好电影的标志是它可以玩弄我们的情绪。这部电影正是这样做的。
整个剧院(全部售罄)在期间充满了笑声
第 1 个实例
演员转导演比尔·帕克斯顿继他备受瞩目的处女作——哥特式恐怖片《脆弱》之后,又推出了这部家庭友好型体育剧,讲述了 1913 年美国的故事。
公开赛,一位年轻的美国球童从卑微的背景中崛起,与他的英国对手比赛
偶像,这场比赛被称为“有史以来最伟大的比赛”。
”我不是高尔夫球迷,这些勉强获胜的弱势体育电影随处可见(最近的成功案例是《奇迹》和《灰姑娘男人》),
但不知何故,这部电影令人着迷
显式构建文本掩码器
[35]:
masker = shap.maskers.Text(classifier.tokenizer)
explainer2 = shap.Explainer(pmodel, masker)
shap_values2 = explainer2(short_data[:2])
shap.plots.text(shap_values2[:, :, 1])
第 0 个实例
昨晚在几个朋友的劝说下,我去看这部电影了。我承认我不太想看,因为就我所知,艾什顿·库彻只会演喜剧。
我错了。库彻把杰克·费舍尔这个角色演得很好,凯文·科斯特纳把本·兰德尔演得非常专业。
一部好电影的标志是它可以玩弄我们的情绪。这部电影正是这样做的。
整个剧院(全部售罄)在期间充满了笑声
第 1 个实例
演员转导演比尔·帕克斯顿继他备受瞩目的处女作——哥特式恐怖片《脆弱》之后,又推出了这部家庭友好型体育剧,讲述了 1913 年美国的故事。
公开赛,一位年轻的美国球童从卑微的背景中崛起,与他的英国对手比赛
偶像,这场比赛被称为“有史以来最伟大的比赛”。
”我不是高尔夫球迷,这些勉强获胜的弱势体育电影随处可见(最近的成功案例是《奇迹》和《灰姑娘男人》),
但不知何故,这部电影令人着迷
探索文本掩码器如何工作
[42]:
masker.shape("I like this movie.")
[42]:
(1, 7)
[48]:
model_args = masker(np.array([True, True, True, True, True, True, True]), "I like this movie.")
model_args
[48]:
(array(['i like this movie .'], dtype='<U19'),)
[49]:
pmodel(*model_args)
[49]:
array([[-8.90780458, 8.90742142]])
[50]:
model_args = masker(np.array([True, True, False, False, True, True, True]), "I like this movie.")
model_args
[50]:
(array(['i [MASK] [MASK] movie .'], dtype='<U23'),)
[51]:
pmodel(*model_args)
[51]:
array([[-3.72092204, 3.72092316]])
[52]:
masker2 = shap.maskers.Text(classifier.tokenizer, mask_token="...", collapse_mask_token=True)
[53]:
model_args2 = masker2(np.array([True, True, False, False, True, True, True]), "I like this movie.")
model_args2
[53]:
(array(['i . . . movie .'], dtype='<U15'),)
[54]:
pmodel(*model_args2)
[54]:
array([[-3.20818664, 3.20818753]])
绘制汇总统计信息和条形图
[55]:
# explain the predictions of the pipeline on the first two samples
shap_values = explainer(short_data[:20])
Partition explainer: 21it [00:11, 1.76it/s]
[56]:
shap.plots.bar(shap_values[0, :, "POSITIVE"])
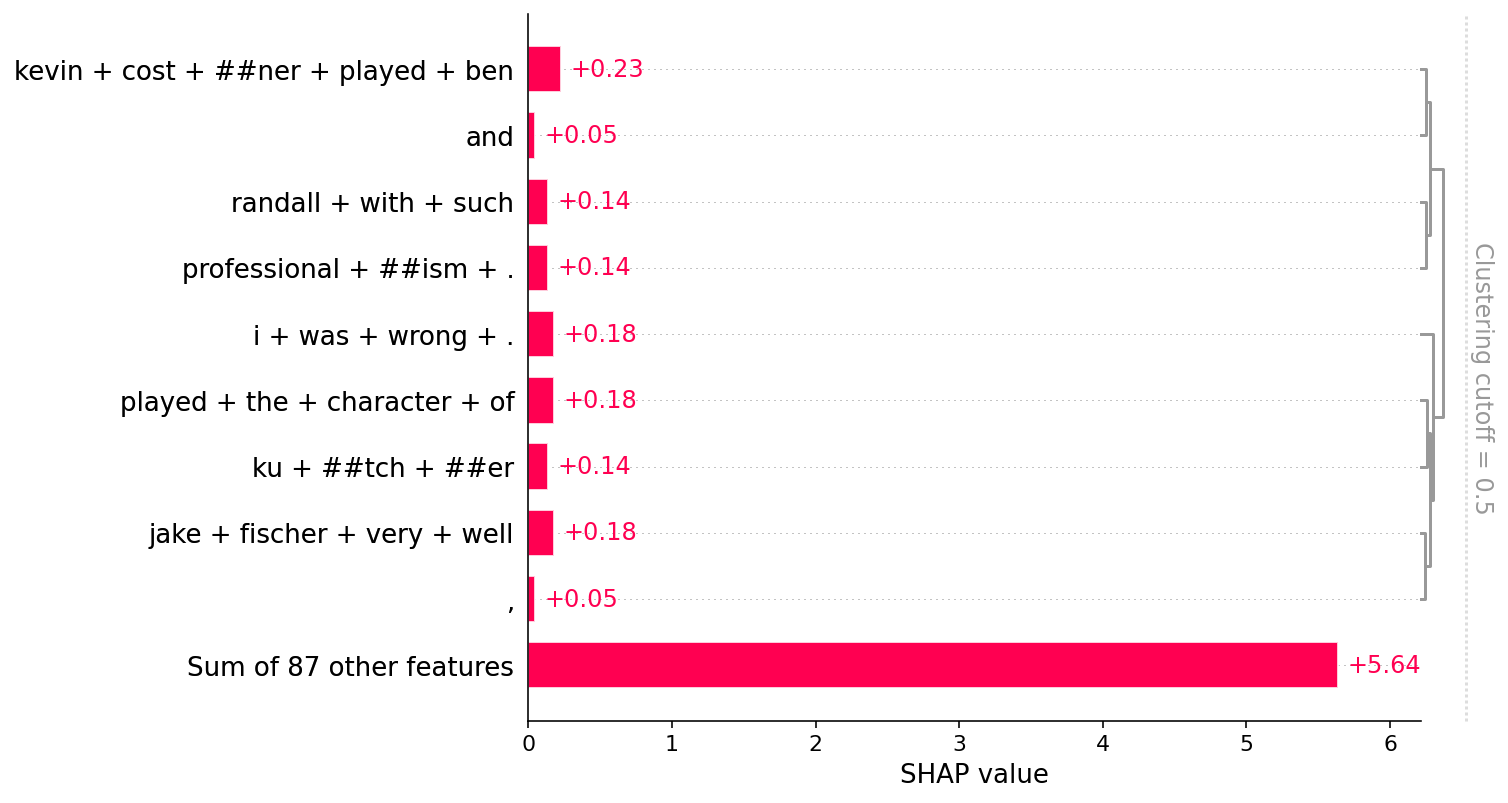
[57]:
shap.plots.bar(shap_values[:, :, "POSITIVE"].mean(0))
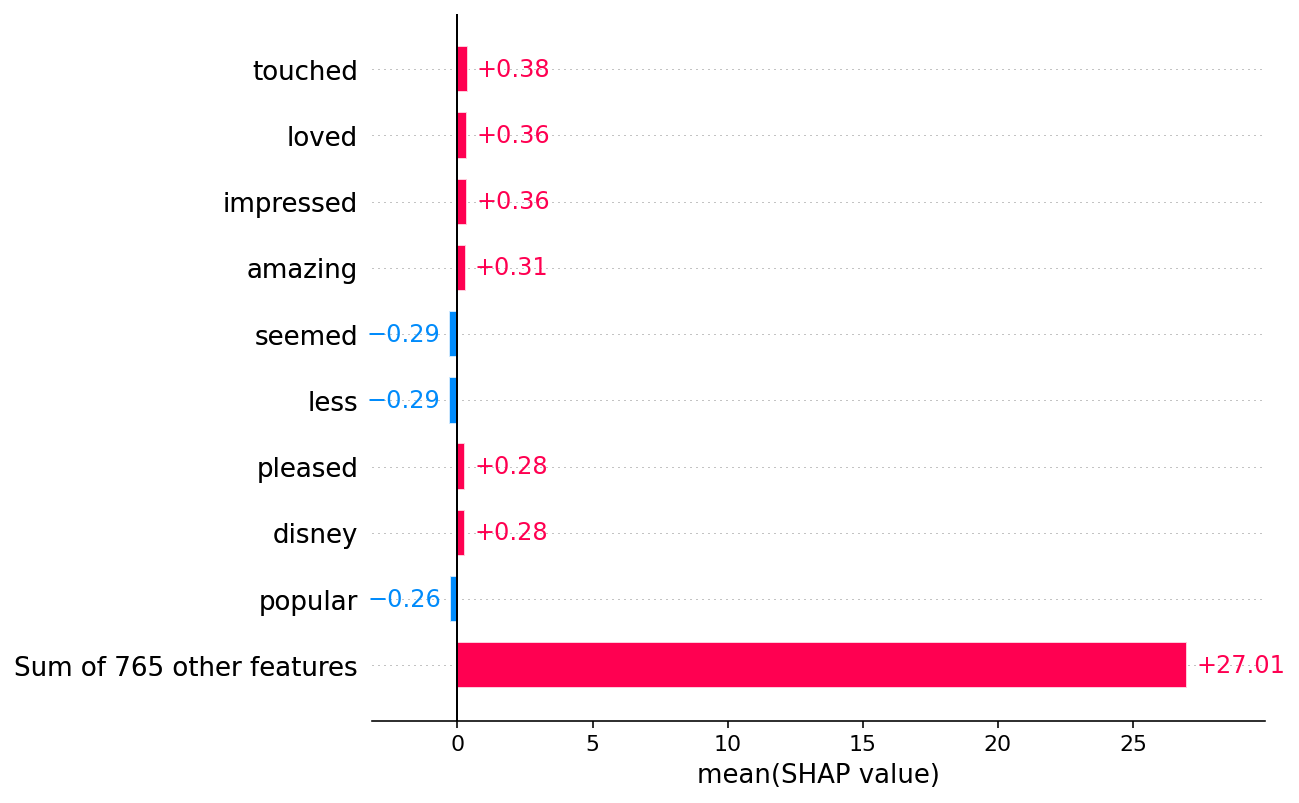
[59]:
shap.plots.bar(shap_values[:, :, "POSITIVE"].mean(0), order=shap.Explanation.argsort)
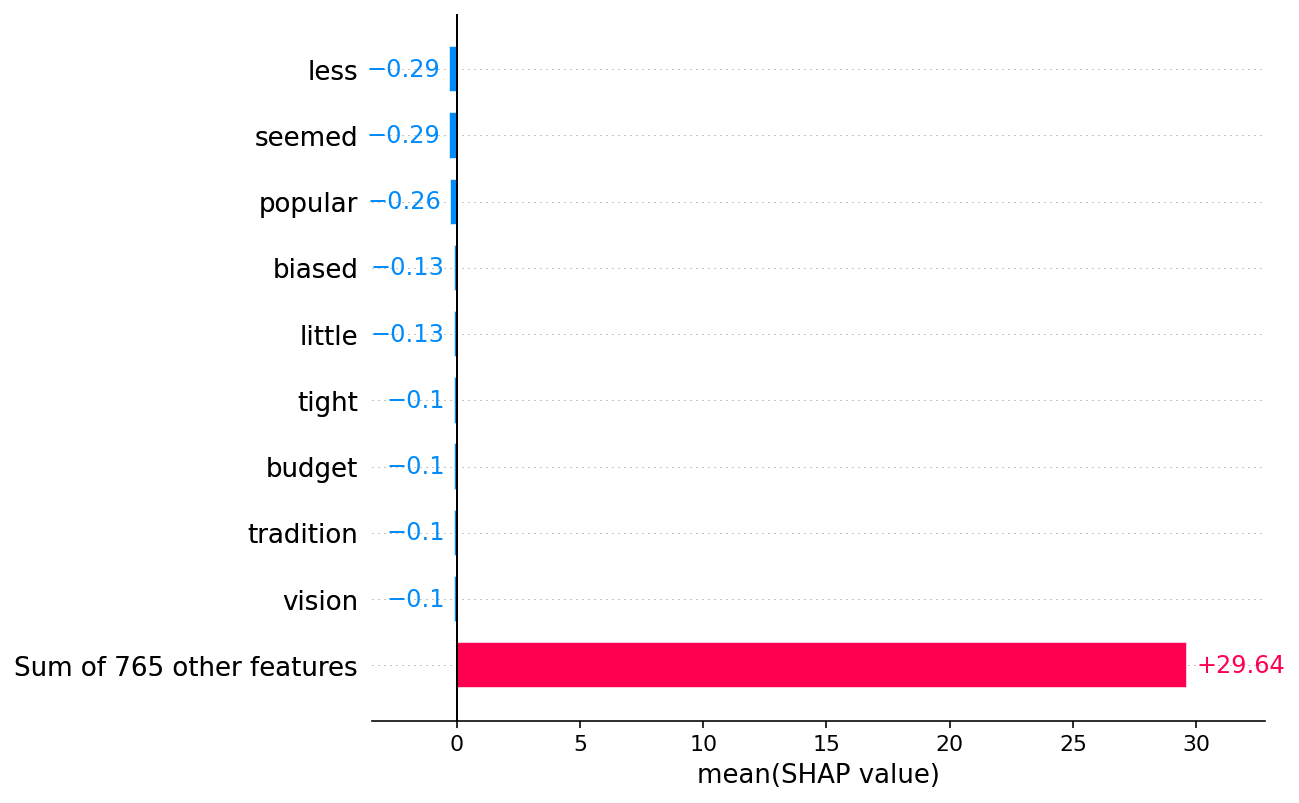
[ ]: