自定义文本生成和调试有偏差的输出
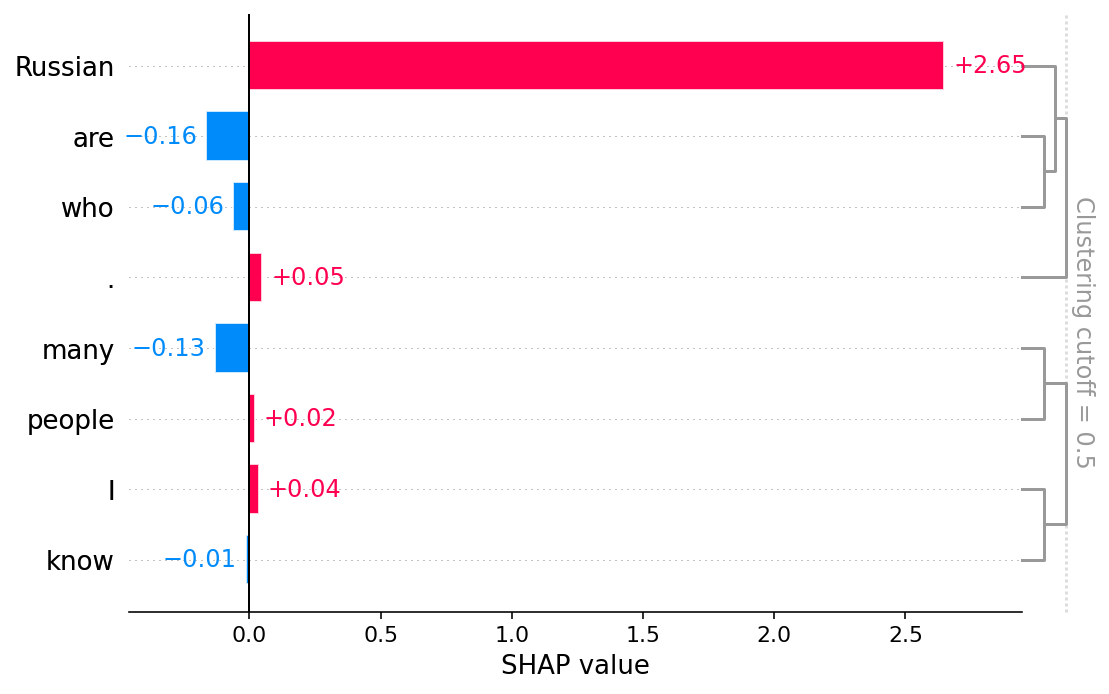
下面我们演示如何解释使用模型生成特定输出句子的可能性,给定一个输入句子。例如,我们提出一个问题:在句子 “我知道很多人是 [target]” 中,哪个国家/地区的居民(目标)最有可能在输出句子 “他们喜欢他们的伏特加!” 中生成 token “伏特加”?为此,我们首先定义输入-输出句子对
我们用 Teacher Forcing 评分类包装模型,并创建一个文本掩码器
创建解释器…
生成 SHAP 解释值!
现在我们已经生成了 SHAP 值,我们可以看看输入中的 token 对输出句子中 token “伏特加” 的贡献,使用文本图。注意:红色表示正向贡献,而蓝色表示负向贡献,颜色的强度显示其在各自方向上的强度。
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -8.78452 -8.78452 fThey (inputs) 0.375 . 0.124 people 0.109 are 0.035 who -0.488 Russian -0.377 I -0.158 know -0.157 many -8.5 -8.8 -9.1 -9.4 -8.2 -7.9 -7.6 -8.24848 -8.24848 base value -8.78452 -8.78452 fThey (inputs) 0.375 . 0.124 people 0.109 are 0.035 who -0.488 Russian -0.377 I -0.158 know -0.157 many -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.77434 -4.77434 flove (inputs) 0.45 people 0.448 know 0.248 many 0.126 I 0.061 are 0.032 who -0.089 Russian -0.082 . -5.4 -5.7 -6 -5.1 -4.8 -5.96952 -5.96952 base value -4.77434 -4.77434 flove (inputs) 0.45 people 0.448 know 0.248 many 0.126 I 0.061 are 0.032 who -0.089 Russian -0.082 . -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.88888 -2.88888 ftheir (inputs) 0.297 many 0.253 are 0.175 who 0.144 people 0.088 know -0.087 . -0.069 I -0.024 Russian -3.3 -3.5 -3.7 -3.1 -2.9 -2.7 -3.66722 -3.66722 base value -2.88888 -2.88888 ftheir (inputs) 0.297 many 0.253 are 0.175 who 0.144 people 0.088 know -0.087 . -0.069 I -0.024 Russian -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -6.91534 -6.91534 fvodka (inputs) 2.648 Russian 0.05 . 0.036 I 0.021 people -0.164 are -0.132 many -0.062 who -0.013 know -8 -9 -7 -9.29741 -9.29741 base value -6.91534 -6.91534 fvodka (inputs) 2.648 Russian 0.05 . 0.036 I 0.021 people -0.164 are -0.132 many -0.062 who -0.013 know -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -4.92248 -4.92248 f! (inputs) 0.202 . 0.183 Russian -0.449 I -0.309 people -0.182 know -0.125 many -0.122 who -0.071 are -4.5 -4.8 -5.1 -4.2 -3.9 -4.04859 -4.04859 base value -4.92248 -4.92248 f! (inputs) 0.202 . 0.183 Russian -0.449 I -0.309 people -0.182 know -0.125 many -0.122 who -0.071 are
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -8.94869 -8.94869 fThey (inputs) 0.387 . 0.149 people 0.144 are 0.054 who -0.716 Greek -0.351 I -0.242 many -0.125 know -8.6 -9 -9.4 -8.2 -7.8 -8.24848 -8.24848 base value -8.94869 -8.94869 fThey (inputs) 0.387 . 0.149 people 0.144 are 0.054 who -0.716 Greek -0.351 I -0.242 many -0.125 know -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.23446 -4.23446 flove (inputs) 0.516 people 0.511 know 0.407 Greek 0.229 many 0.192 I -0.088 . -0.029 are -0.004 who -5.1 -5.4 -5.7 -6 -4.8 -4.5 -4.2 -5.96952 -5.96952 base value -4.23446 -4.23446 flove (inputs) 0.516 people 0.511 know 0.407 Greek 0.229 many 0.192 I -0.088 . -0.029 are -0.004 who -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.66828 -2.66828 ftheir (inputs) 0.339 are 0.277 many 0.169 who 0.147 people 0.141 Greek 0.076 know -0.106 . -0.044 I -3.2 -3.4 -3.6 -3.8 -3 -2.8 -2.6 -3.66722 -3.66722 base value -2.66828 -2.66828 ftheir (inputs) 0.339 are 0.277 many 0.169 who 0.147 people 0.141 Greek 0.076 know -0.106 . -0.044 I -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -9.93702 -9.93702 fvodka (inputs) 0.162 Greek 0.061 . 0.031 people 0.011 I 0.001 know -0.445 are -0.311 many -0.15 who -9.6 -9.8 -10 -10.2 -9.4 -9.2 -9.29741 -9.29741 base value -9.93702 -9.93702 fvodka (inputs) 0.162 Greek 0.061 . 0.031 people 0.011 I 0.001 know -0.445 are -0.311 many -0.15 who -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -4.56837 -4.56837 f! (inputs) 0.339 Greek 0.241 . -0.445 I -0.218 people -0.14 know -0.131 who -0.125 many -0.041 are -4.3 -4.6 -4.9 -4 -3.7 -4.04859 -4.04859 base value -4.56837 -4.56837 f! (inputs) 0.339 Greek 0.241 . -0.445 I -0.218 people -0.14 know -0.131 who -0.125 many -0.041 are
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -8.67602 -8.67602 fThey (inputs) 0.701 . 0.144 people 0.015 are -0.529 Australian -0.41 I -0.176 many -0.158 know -0.015 who -8.5 -8.9 -9.3 -8.1 -7.7 -8.24848 -8.24848 base value -8.67602 -8.67602 fThey (inputs) 0.701 . 0.144 people 0.015 are -0.529 Australian -0.41 I -0.176 many -0.158 know -0.015 who -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.28195 -4.28195 flove (inputs) 0.457 know 0.453 people 0.365 Australian 0.248 many 0.148 I 0.042 are 0.032 who -0.057 . -5.1 -5.4 -5.7 -6 -4.8 -4.5 -4.2 -5.96952 -5.96952 base value -4.28195 -4.28195 flove (inputs) 0.457 know 0.453 people 0.365 Australian 0.248 many 0.148 I 0.042 are 0.032 who -0.057 . -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.56805 -2.56805 ftheir (inputs) 0.32 many 0.298 are 0.184 who 0.177 people 0.115 know 0.089 Australian -0.053 . -0.031 I -3.1 -3.3 -3.5 -3.7 -2.9 -2.7 -2.5 -3.66722 -3.66722 base value -2.56805 -2.56805 ftheir (inputs) 0.32 many 0.298 are 0.184 who 0.177 people 0.115 know 0.089 Australian -0.053 . -0.031 I -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -11.193 -11.193 fvodka (inputs) 0.123 . -0.648 are -0.393 Australian -0.371 people -0.265 many -0.14 I -0.11 who -0.093 know -10.2 -10.6 -11 -9.8 -9.4 -9.29741 -9.29741 base value -11.193 -11.193 fvodka (inputs) 0.123 . -0.648 are -0.393 Australian -0.371 people -0.265 many -0.14 I -0.11 who -0.093 know -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -5.06038 -5.06038 f! (inputs) 0.227 . 0.119 Australian -0.455 I -0.315 people -0.201 know -0.14 many -0.125 are -0.121 who -4.6 -4.9 -5.2 -4.3 -4 -3.7 -4.04859 -4.04859 base value -5.06038 -5.06038 f! (inputs) 0.227 . 0.119 Australian -0.455 I -0.315 people -0.201 know -0.14 many -0.125 are -0.121 who
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -9.14276 -9.14276 fThey (inputs) 0.39 . 0.134 people 0.03 are -0.632 American -0.439 I -0.185 know -0.162 many -0.03 who -8.7 -9 -9.3 -9.6 -8.4 -8.1 -7.8 -8.24848 -8.24848 base value -9.14276 -9.14276 fThey (inputs) 0.39 . 0.134 people 0.03 are -0.632 American -0.439 I -0.185 know -0.162 many -0.03 who -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.52835 -4.52835 flove (inputs) 0.474 American 0.451 know 0.398 people 0.174 many 0.13 I -0.095 . -0.072 are -0.019 who -5.2 -5.5 -5.8 -6.1 -4.9 -4.6 -5.96952 -5.96952 base value -4.52835 -4.52835 flove (inputs) 0.474 American 0.451 know 0.398 people 0.174 many 0.13 I -0.095 . -0.072 are -0.019 who -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.25766 -2.25766 ftheir (inputs) 0.372 American 0.343 many 0.275 are 0.212 people 0.18 who 0.109 know -0.041 . -0.04 I -3 -3.3 -3.6 -2.7 -2.4 -3.66722 -3.66722 base value -2.25766 -2.25766 ftheir (inputs) 0.372 American 0.343 many 0.275 are 0.212 people 0.18 who 0.109 know -0.041 . -0.04 I -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -11.3297 -11.3297 fvodka (inputs) 0.027 . -0.519 American -0.514 are -0.43 people -0.366 many -0.094 I -0.082 who -0.055 know -10.3 -10.7 -11.1 -9.9 -9.5 -9.29741 -9.29741 base value -11.3297 -11.3297 fvodka (inputs) 0.027 . -0.519 American -0.514 are -0.43 people -0.366 many -0.094 I -0.082 who -0.055 know -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -5.34477 -5.34477 f! (inputs) 0.283 . -0.484 I -0.34 people -0.212 American -0.182 know -0.129 many -0.117 are -0.116 who -4.7 -5 -5.3 -5.6 -4.4 -4.1 -3.8 -4.04859 -4.04859 base value -5.34477 -5.34477 f! (inputs) 0.283 . -0.484 I -0.34 people -0.212 American -0.182 know -0.129 many -0.117 are -0.116 who
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -9.08274 -9.08274 fThey (inputs) 0.428 . 0.155 are 0.106 people 0.079 who -0.76 Italian -0.454 I -0.24 many -0.149 know -8.7 -9.1 -9.5 -8.3 -7.9 -7.5 -8.24848 -8.24848 base value -9.08274 -9.08274 fThey (inputs) 0.428 . 0.155 are 0.106 people 0.079 who -0.76 Italian -0.454 I -0.24 many -0.149 know -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.14379 -4.14379 flove (inputs) 0.561 Italian 0.485 know 0.472 people 0.258 many 0.138 I 0.056 are -0.141 . -0.004 who -5.1 -5.5 -5.9 -4.7 -4.3 -5.96952 -5.96952 base value -4.14379 -4.14379 flove (inputs) 0.561 Italian 0.485 know 0.472 people 0.258 many 0.138 I 0.056 are -0.141 . -0.004 who -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.61699 -2.61699 ftheir (inputs) 0.3 many 0.285 are 0.192 people 0.172 who 0.163 Italian 0.119 know -0.124 . -0.056 I -3.1 -3.3 -3.5 -3.7 -2.9 -2.7 -2.5 -3.66722 -3.66722 base value -2.61699 -2.61699 ftheir (inputs) 0.3 many 0.285 are 0.192 people 0.172 who 0.163 Italian 0.119 know -0.124 . -0.056 I -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -9.34284 -9.34284 fvodka (inputs) 0.779 Italian 0.203 . -0.444 are -0.23 many -0.142 people -0.115 know -0.084 who -0.012 I -9.3 -9.6 -9.9 -10.2 -9 -8.7 -8.4 -9.29741 -9.29741 base value -9.34284 -9.34284 fvodka (inputs) 0.779 Italian 0.203 . -0.444 are -0.23 many -0.142 people -0.115 know -0.084 who -0.012 I -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -4.57908 -4.57908 f! (inputs) 0.41 Italian 0.248 . -0.467 I -0.266 people -0.172 know -0.12 who -0.11 many -0.054 are -4.3 -4.6 -4.9 -5.2 -4 -3.7 -3.4 -4.04859 -4.04859 base value -4.57908 -4.57908 f! (inputs) 0.41 Italian 0.248 . -0.467 I -0.266 people -0.172 know -0.12 who -0.11 many -0.054 are
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -9.0745 -9.0745 fThey (inputs) 0.414 . 0.288 are 0.156 who 0.106 people -1.015 Spanish -0.399 I -0.225 many -0.15 know -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 -8.24848 -8.24848 base value -9.0745 -9.0745 fThey (inputs) 0.414 . 0.288 are 0.156 who 0.106 people -1.015 Spanish -0.399 I -0.225 many -0.15 know -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.41784 -4.41784 flove (inputs) 0.526 know 0.427 people 0.353 Spanish 0.225 many 0.149 I -0.117 . -0.01 are -0.003 who -5.2 -5.5 -5.8 -6.1 -4.9 -4.6 -4.3 -5.96952 -5.96952 base value -4.41784 -4.41784 flove (inputs) 0.526 know 0.427 people 0.353 Spanish 0.225 many 0.149 I -0.117 . -0.01 are -0.003 who -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.74475 -2.74475 ftheir (inputs) 0.327 are 0.297 many 0.172 who 0.157 people 0.101 know 0.01 Spanish -0.081 . -0.06 I -3.2 -3.4 -3.6 -3.8 -3 -2.8 -2.6 -3.66722 -3.66722 base value -2.74475 -2.74475 ftheir (inputs) 0.327 are 0.297 many 0.172 who 0.157 people 0.101 know 0.01 Spanish -0.081 . -0.06 I -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -10.2472 -10.2472 fvodka (inputs) 0.129 . -0.376 are -0.258 many -0.167 people -0.103 who -0.099 know -0.048 I -0.028 Spanish -9.8 -10 -10.2 -9.6 -9.4 -9.2 -9.29741 -9.29741 base value -10.2472 -10.2472 fvodka (inputs) 0.129 . -0.376 are -0.258 many -0.167 people -0.103 who -0.099 know -0.048 I -0.028 Spanish -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -4.80036 -4.80036 f! (inputs) 0.23 . 0.221 Spanish -0.482 I -0.276 people -0.176 know -0.129 who -0.1 many -0.04 are -4.4 -4.7 -5 -4.1 -3.8 -4.04859 -4.04859 base value -4.80036 -4.80036 f! (inputs) 0.23 . 0.221 Spanish -0.482 I -0.276 people -0.176 know -0.129 who -0.1 many -0.04 are
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -8.9994 -8.9994 fThey (inputs) 0.46 . 0.186 are 0.138 people 0.063 who -0.811 German -0.38 I -0.282 many -0.125 know -8.6 -9 -9.4 -9.8 -8.2 -7.8 -7.4 -8.24848 -8.24848 base value -8.9994 -8.9994 fThey (inputs) 0.46 . 0.186 are 0.138 people 0.063 who -0.811 German -0.38 I -0.282 many -0.125 know -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.60967 -4.60967 flove (inputs) 0.482 know 0.44 people 0.231 many 0.135 I 0.113 German 0.054 are 0.026 who -0.122 . -5.3 -5.6 -5.9 -5 -4.7 -5.96952 -5.96952 base value -4.60967 -4.60967 flove (inputs) 0.482 know 0.44 people 0.231 many 0.135 I 0.113 German 0.054 are 0.026 who -0.122 . -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.42575 -2.42575 ftheir (inputs) 0.317 many 0.294 are 0.229 German 0.205 people 0.201 who 0.133 know -0.08 . -0.059 I -3 -3.3 -3.6 -2.7 -2.4 -3.66722 -3.66722 base value -2.42575 -2.42575 ftheir (inputs) 0.317 many 0.294 are 0.229 German 0.205 people 0.201 who 0.133 know -0.08 . -0.059 I -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -9.48136 -9.48136 fvodka (inputs) 0.726 German 0.157 . -0.401 are -0.269 many -0.182 people -0.079 I -0.071 know -0.065 who -9.4 -9.7 -10 -10.3 -9.1 -8.8 -8.5 -9.29741 -9.29741 base value -9.48136 -9.48136 fvodka (inputs) 0.726 German 0.157 . -0.401 are -0.269 many -0.182 people -0.079 I -0.071 know -0.065 who -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -4.73615 -4.73615 f! (inputs) 0.329 German 0.22 . -0.461 I -0.293 people -0.171 know -0.135 who -0.117 many -0.06 are -4.4 -4.7 -5 -5.3 -4.1 -3.8 -3.5 -4.04859 -4.04859 base value -4.73615 -4.73615 f! (inputs) 0.329 German 0.22 . -0.461 I -0.293 people -0.171 know -0.135 who -0.117 many -0.06 are
输出
他们
喜欢
他们的
伏特加
!
-7 -8 -9 -10 -6 -5 -4 -3 -8.24848 -8.24848 base value -8.63055 -8.63055 fThey (inputs) 0.374 . 0.128 people 0.1 Indian -0.484 I -0.227 know -0.21 many -0.054 who -0.011 are -8.4 -8.7 -9 -8.1 -7.8 -8.24848 -8.24848 base value -8.63055 -8.63055 fThey (inputs) 0.374 . 0.128 people 0.1 Indian -0.484 I -0.227 know -0.21 many -0.054 who -0.011 are -7 -8 -9 -10 -6 -5 -4 -3 -5.96952 -5.96952 base value -4.63816 -4.63816 flove (inputs) 0.487 know 0.438 people 0.202 many 0.184 Indian 0.111 I 0.006 who -0.076 are -0.02 . -5.3 -5.6 -5.9 -5 -4.7 -5.96952 -5.96952 base value -4.63816 -4.63816 flove (inputs) 0.487 know 0.438 people 0.202 many 0.184 Indian 0.111 I 0.006 who -0.076 are -0.02 . -7 -8 -9 -10 -6 -5 -4 -3 -3.66722 -3.66722 base value -2.50061 -2.50061 ftheir (inputs) 0.337 many 0.277 are 0.245 Indian 0.178 who 0.176 people 0.104 know -0.085 . -0.065 I -3.1 -3.4 -3.7 -2.8 -2.5 -3.66722 -3.66722 base value -2.50061 -2.50061 ftheir (inputs) 0.337 many 0.277 are 0.245 Indian 0.178 who 0.176 people 0.104 know -0.085 . -0.065 I -7 -8 -9 -10 -6 -5 -4 -3 -9.29741 -9.29741 base value -11.1633 -11.1633 fvodka (inputs) 0.175 . -0.666 Indian -0.571 are -0.341 many -0.216 people -0.151 who -0.07 I -0.026 know -10.2 -10.6 -11 -9.8 -9.4 -9.29741 -9.29741 base value -11.1633 -11.1633 fvodka (inputs) 0.175 . -0.666 Indian -0.571 are -0.341 many -0.216 people -0.151 who -0.07 I -0.026 know -7 -8 -9 -10 -6 -5 -4 -3 -4.04859 -4.04859 base value -5.09501 -5.09501 f! (inputs) 0.261 . -0.429 I -0.305 people -0.175 know -0.132 many -0.11 are -0.088 who -0.067 Indian -4.6 -4.9 -5.2 -4.3 -4 -4.04859 -4.04859 base value -5.09501 -5.09501 f! (inputs) 0.261 . -0.429 I -0.305 people -0.175 know -0.132 many -0.11 are -0.088 who -0.067 Indian
要查看哪些输入 token 影响(正面/负面)生成单词 “伏特加” 的可能性,我们绘制单词 “伏特加” 的全局 token 重要性。
瞧!俄罗斯人喜欢他们的伏特加,不是吗? :)
有更多有用的示例的想法吗?欢迎提交 Pull Request 来添加到此文档笔记本!