GPUTree 解释器
此笔记本演示了如何在一些简单的数据集上使用 GPUTree 解释器。与 Tree 解释器类似,GPUTree 解释器专为基于树的机器学习模型设计,但它旨在利用 NVIDIA GPU 加速计算。
请注意,为了使用 GPUTree 解释器,您需要拥有 NVIDIA GPU,并且 SHAP 需要已编译以支持您系统上当前的 GPU 库。在最新的 Ubuntu 服务器上,实现此目的的步骤是
通过从终端运行
nvcc命令(CUDA 编译器)来检查以确保您已安装 NVIDIA CUDA 工具包。如果找不到此命令,则您需要使用类似sudo apt install nvidia-cuda-toolkit的命令安装它。安装 NVIDIA CUDA 工具包后,您需要设置 CUDA_PATH 环境变量。如果
which nvcc产生/usr/bin/nvcc,那么您可以运行export CUDA_PATH=/usr。通过使用
git clone https://github.com/shap/shap.git克隆 shap repo,然后运行python setup.py install --user,使用 CUDA 支持构建 SHAP。
如果您在执行上述说明时遇到问题,请通过确保在开始新的安装之前 import shap 失败来确保您没有旧版本的 SHAP。
下面我们演示如何在简单的成人收入分类数据集和模型上使用 GPUTree 解释器。
[1]:
import xgboost
import shap
# get a dataset on income prediction
X, y = shap.datasets.adult()
# train an XGBoost model (but any other model type would also work)
model = xgboost.XGBClassifier()
model.fit(X, y)
[1]:
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=0, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
具有独立(Shapley 值)掩码的表格数据
[2]:
# build a Permutation explainer and explain the model predictions on the given dataset
explainer = shap.explainers.GPUTree(model, X)
shap_values = explainer(X)
# get just the explanations for the positive class
shap_values = shap_values
绘制全局摘要
[3]:
shap.plots.bar(shap_values)

绘制单个实例
[4]:
shap.plots.waterfall(shap_values[0])

交互值
GPUTree 支持 Shapley 泰勒交互值(是对 Tree 解释器最初提供的功能的改进)。
[5]:
explainer2 = shap.explainers.GPUTree(model, feature_perturbation="tree_path_dependent")
interaction_shap_values = explainer2(X[:100], interactions=True)
[6]:
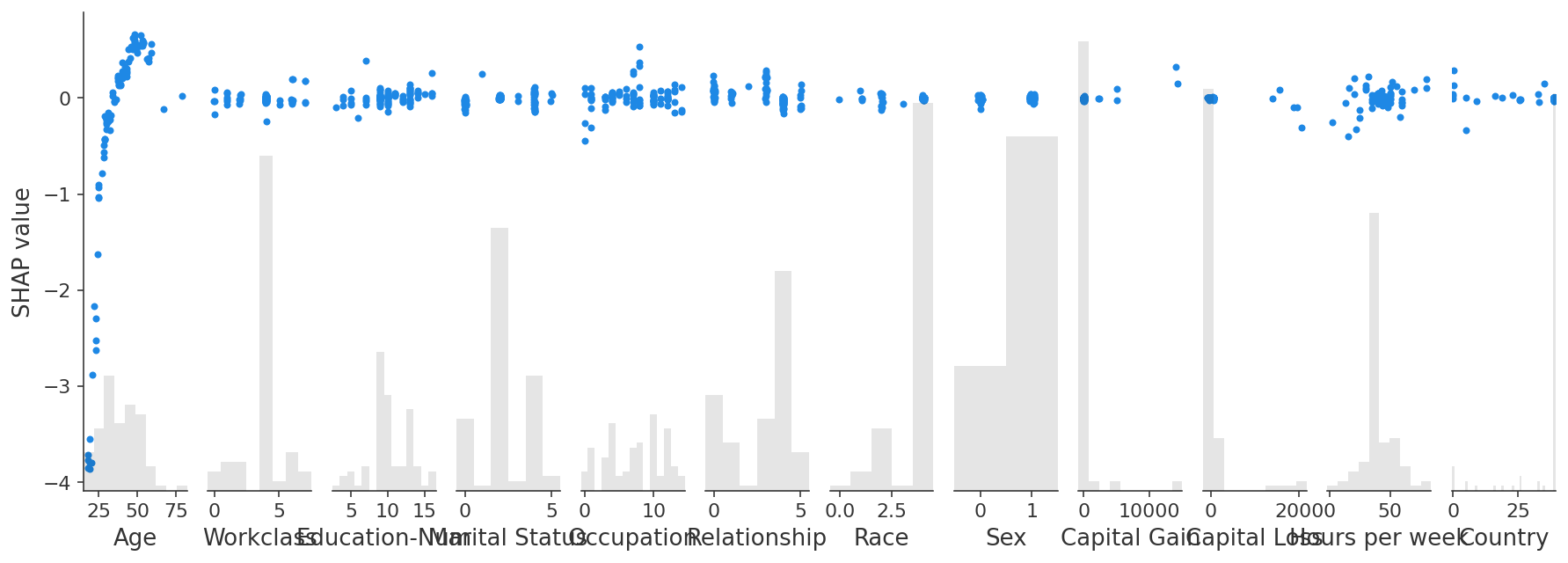
shap.plots.scatter(interaction_shap_values[:, :, 0])
有更多有用的示例的想法吗? 欢迎提交拉取请求以添加到此文档笔记本!