Permutation 解释器
本笔记本演示了如何在一些简单的数据集上使用 Permutation 解释器。Permutation 解释器是模型无关的,因此它可以计算任何模型的 Shapley 值和 Owen 值。它的工作原理是迭代特征的完整正向和反向排列。通过这样做,每次更改一个特征,我们可以最大限度地减少所需的模型评估次数,并始终确保我们满足效率,无论我们选择使用原始模型的多少次执行来近似特征归因值。因此,计算出的 SHAP 值虽然是近似值,但确实完全加起来等于模型的基本值与每个解释实例的模型输出之间的差异。
由于 Permutation 解释器具有重要的性能优化,并且不需要像 Kernel 解释器那样的正则化参数调整,因此 Permutation 解释器是用于表格数据集的默认模型无关解释器,这些表格数据集具有比 Exact 解释器更适合的特征。
下面我们演示如何在简单的成人收入分类数据集和模型上使用 Permutation 解释器。
[1]:
import xgboost
import shap
# get a dataset on income prediction
X, y = shap.datasets.adult()
# train an XGBoost model (but any other model type would also work)
model = xgboost.XGBClassifier()
model.fit(X, y);
使用独立(Shapley 值)掩码的表格数据
[2]:
# build a Permutation explainer and explain the model predictions on the given dataset
explainer = shap.explainers.Permutation(model.predict_proba, X)
shap_values = explainer(X[:100])
# get just the explanations for the positive class
shap_values = shap_values[..., 1]
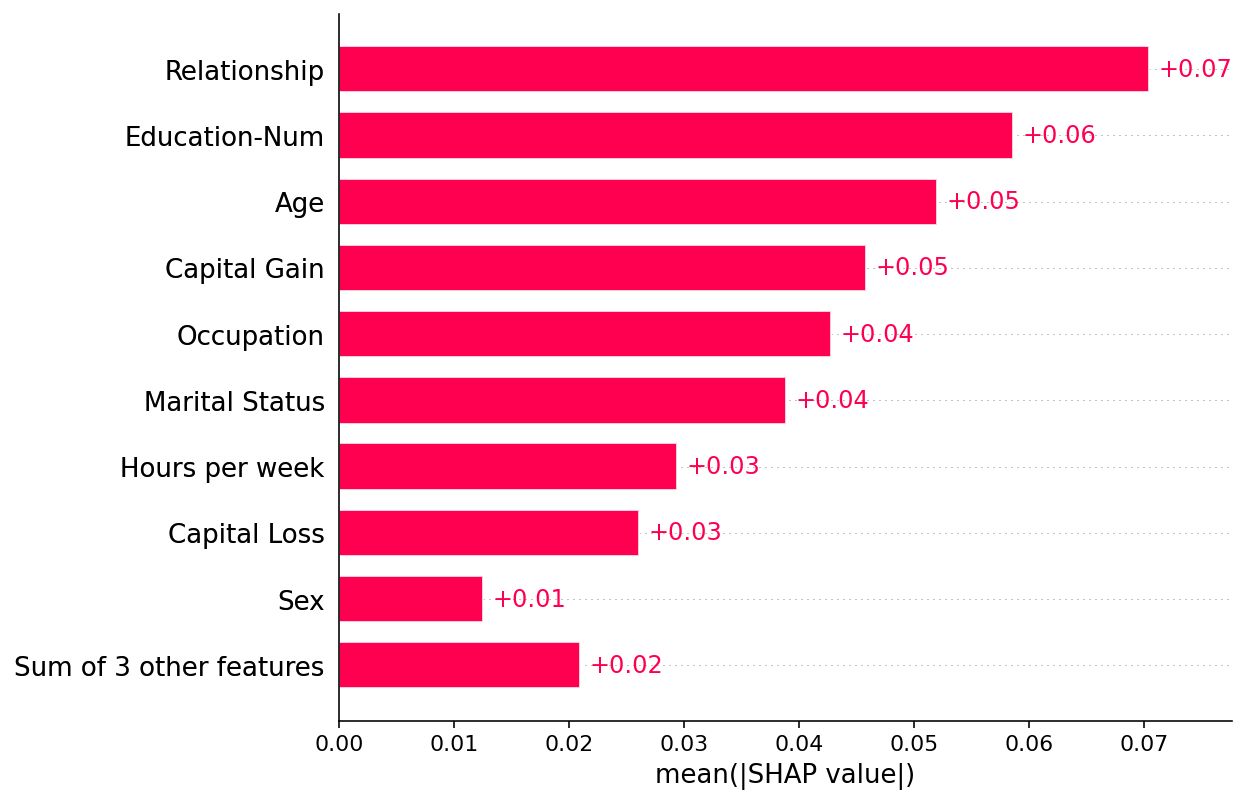
绘制全局摘要
[3]:
shap.plots.bar(shap_values)
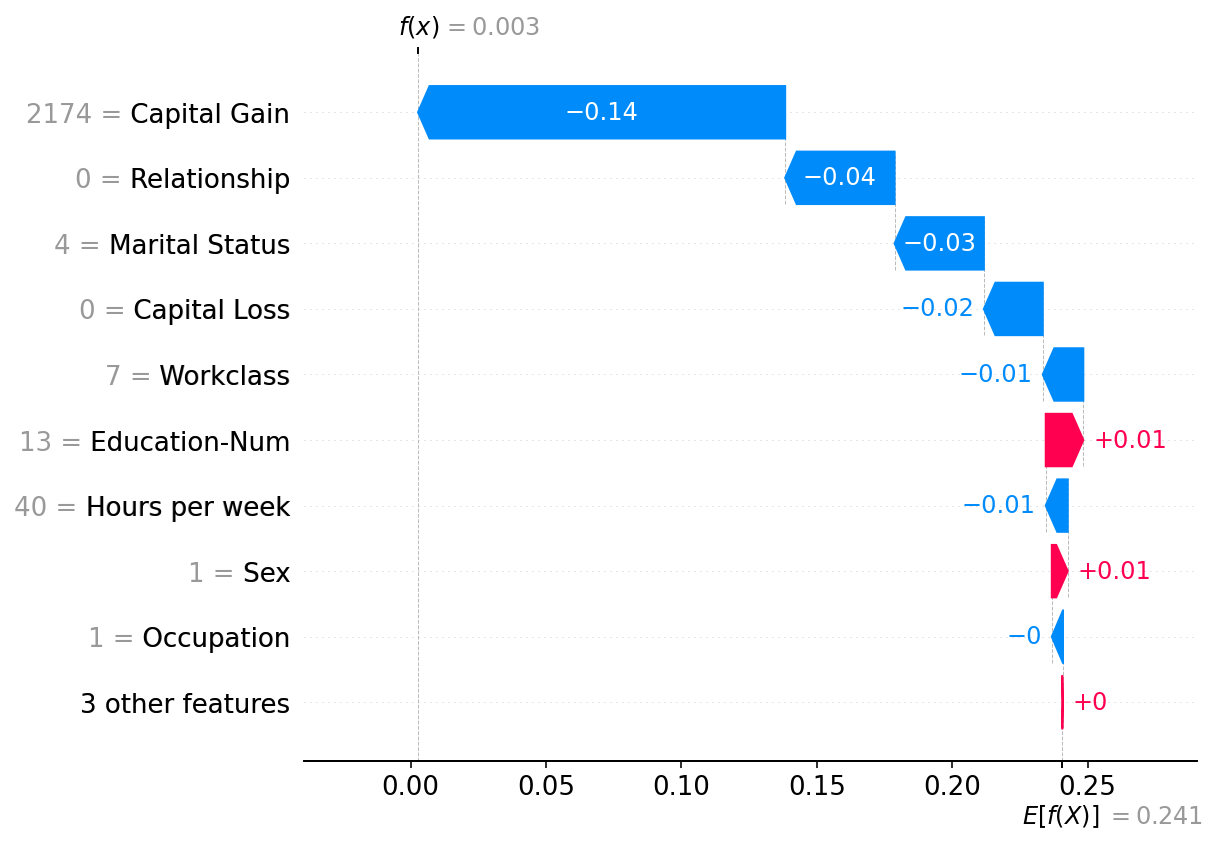
绘制单个实例
[4]:
shap.plots.waterfall(shap_values[0])
使用分区(Owen 值)掩码的表格数据
虽然 Shapley 值来自于独立于其他特征处理每个特征,但在模型输入上强制结构通常很有用。强制这种结构会产生一个结构化博弈(即一个关于有效输入特征联盟规则的博弈),当该结构是一组嵌套的特征分组时,我们得到 Owen 值作为 Shapley 值对组的递归应用。在 SHAP 中,我们将分区推向极限,并构建一个二叉分层聚类树来表示数据的结构。这种结构可以通过多种方式选择,但对于表格数据,从输入特征之间关于输出标签的信息冗余性构建结构通常很有帮助。这就是我们下面所做的
[5]:
# build a clustering of the features based on shared information about y
clustering = shap.utils.hclust(X, y)
[6]:
# above we implicitly used shap.maskers.Independent by passing a raw dataframe as the masker
# now we explicitly use a Partition masker that uses the clustering we just computed
masker = shap.maskers.Partition(X, clustering=clustering)
# build a Permutation explainer and explain the model predictions on the given dataset
explainer = shap.explainers.Permutation(model.predict_proba, masker)
shap_values2 = explainer(X[:100])
# get just the explanations for the positive class
shap_values2 = shap_values2[..., 1]
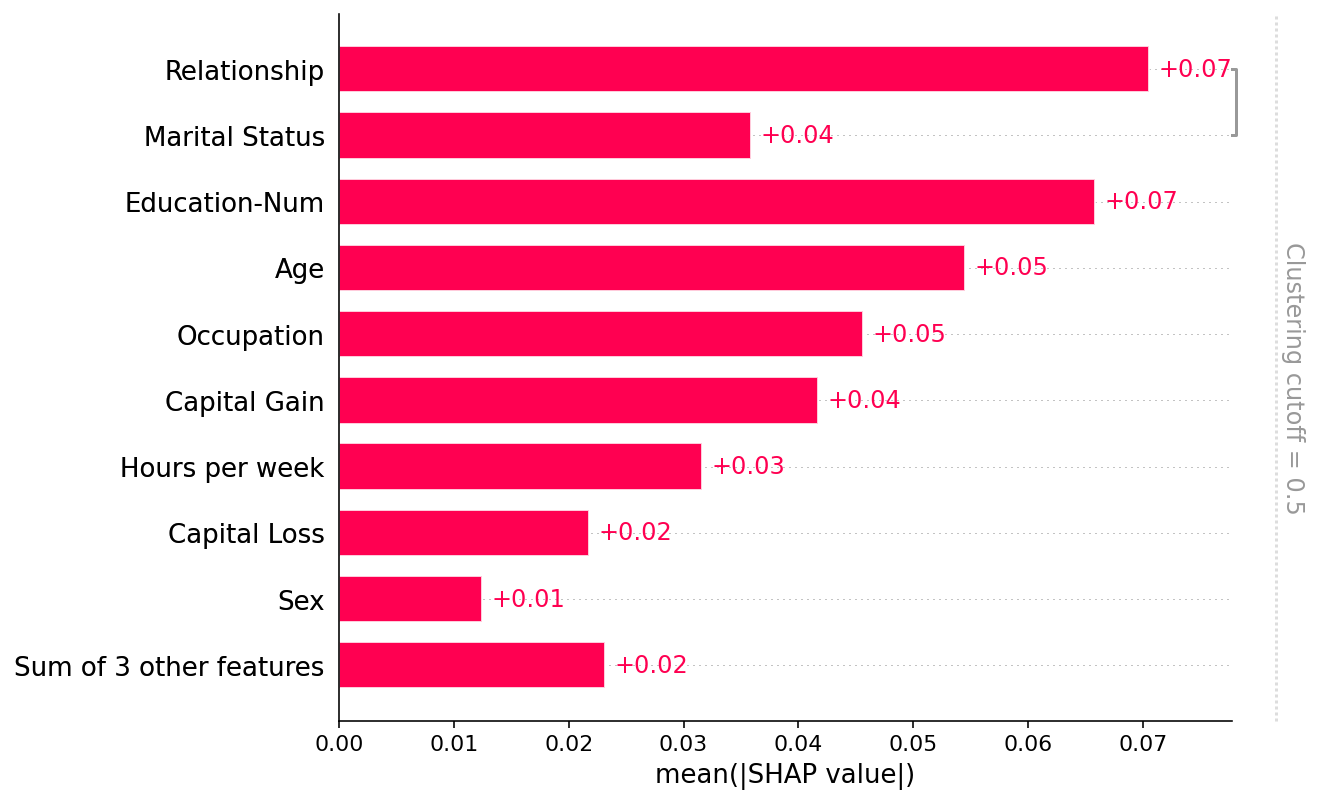
绘制全局摘要
请注意,只有 Relationship 和 Marital status 特征彼此共享超过 50% 的解释能力(以 R2 衡量),因此聚类树的所有其他部分都通过默认的 clustering_cutoff=0.5 设置删除
[7]:
shap.plots.bar(shap_values2)
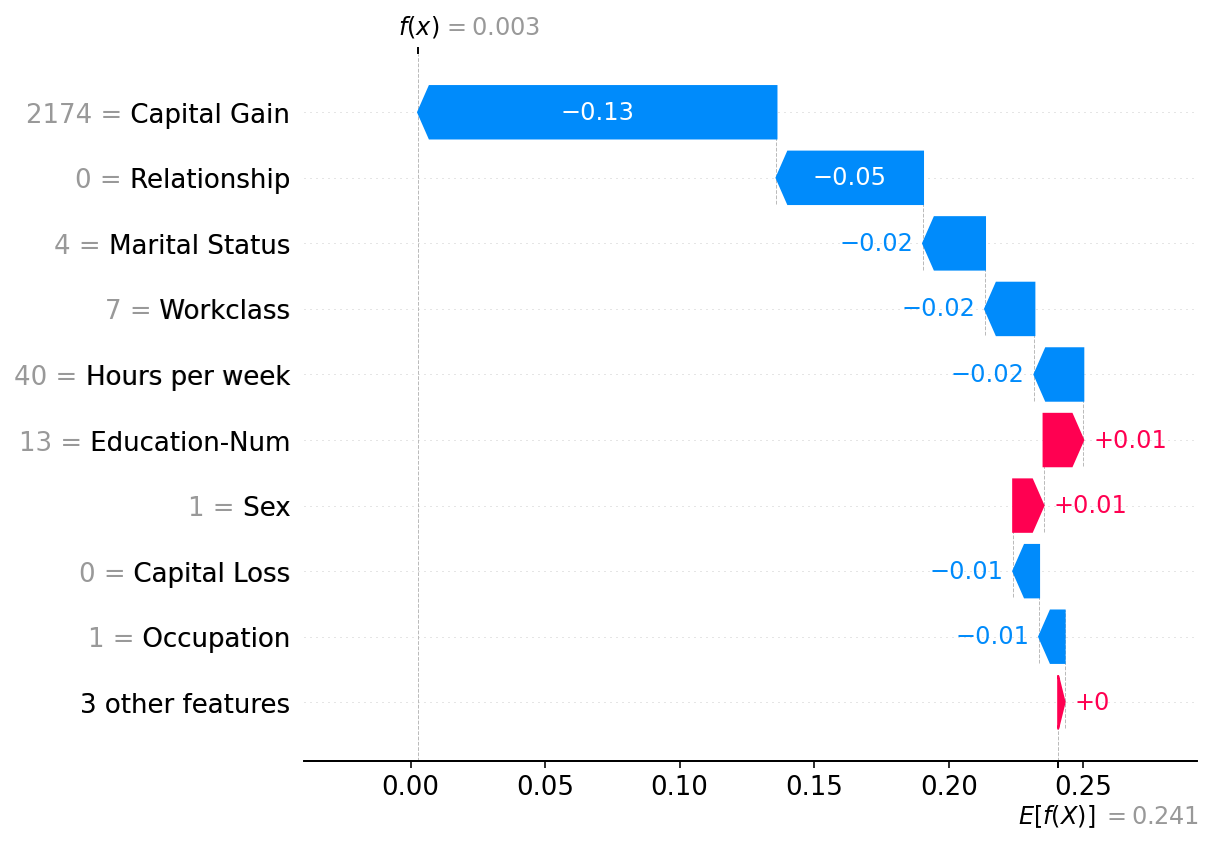
绘制单个实例
请注意,上面 Independent 掩码器的解释和这里的 Partition 掩码器之间存在很强的相似性。总的来说,表格数据的这些方法之间的区别并不大,尽管 Partition 掩码器允许更快的运行时和可能更真实的模型输入操作(因为聚类特征组一起被掩码/取消掩码)。
[8]:
shap.plots.waterfall(shap_values2[0])
有更多有用的示例的想法吗? 鼓励提交 pull request 以添加到此文档笔记本!