beeswarm 图
此 notebook 旨在演示(并因此记录)如何使用 shap.plots.beeswarm 函数。它使用在经典的 UCI 成人收入数据集上训练的 XGBoost 模型(这是一个分类任务,用于预测人们在 1990 年代是否收入超过 5 万美元)。
[1]:
import xgboost
import shap
# train XGBoost model
X, y = shap.datasets.adult()
model = xgboost.XGBClassifier().fit(X, y)
# compute SHAP values
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
98%|===================| 32071/32561 [00:58<00:00]
一个简单的 beeswarm 摘要图
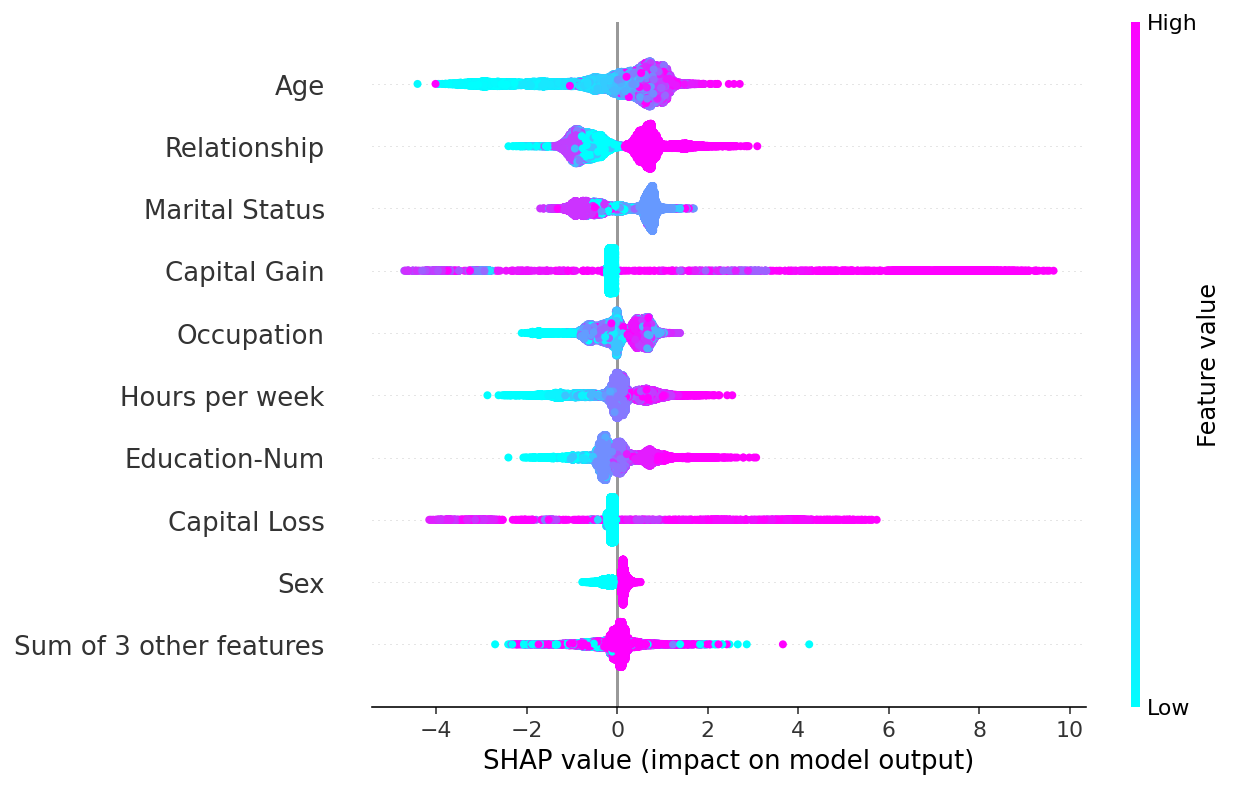
beeswarm 图旨在显示一个信息密集的摘要,说明数据集中最重要的特征如何影响模型的输出。给定解释的每个实例都由每个特征行上的一个点表示。点的 x 位置由该特征的 SHAP 值 (shap_values.value[instance,feature]) 确定,点沿每个特征行“堆积”以显示密度。颜色用于显示特征的原始值 (shap_values.data[instance,feature])。在下面的图中,我们可以看到“年龄”是平均而言最重要的特征,并且年轻人(蓝色)不太可能收入超过 5 万美元。
[2]:
shap.plots.beeswarm(shap_values)
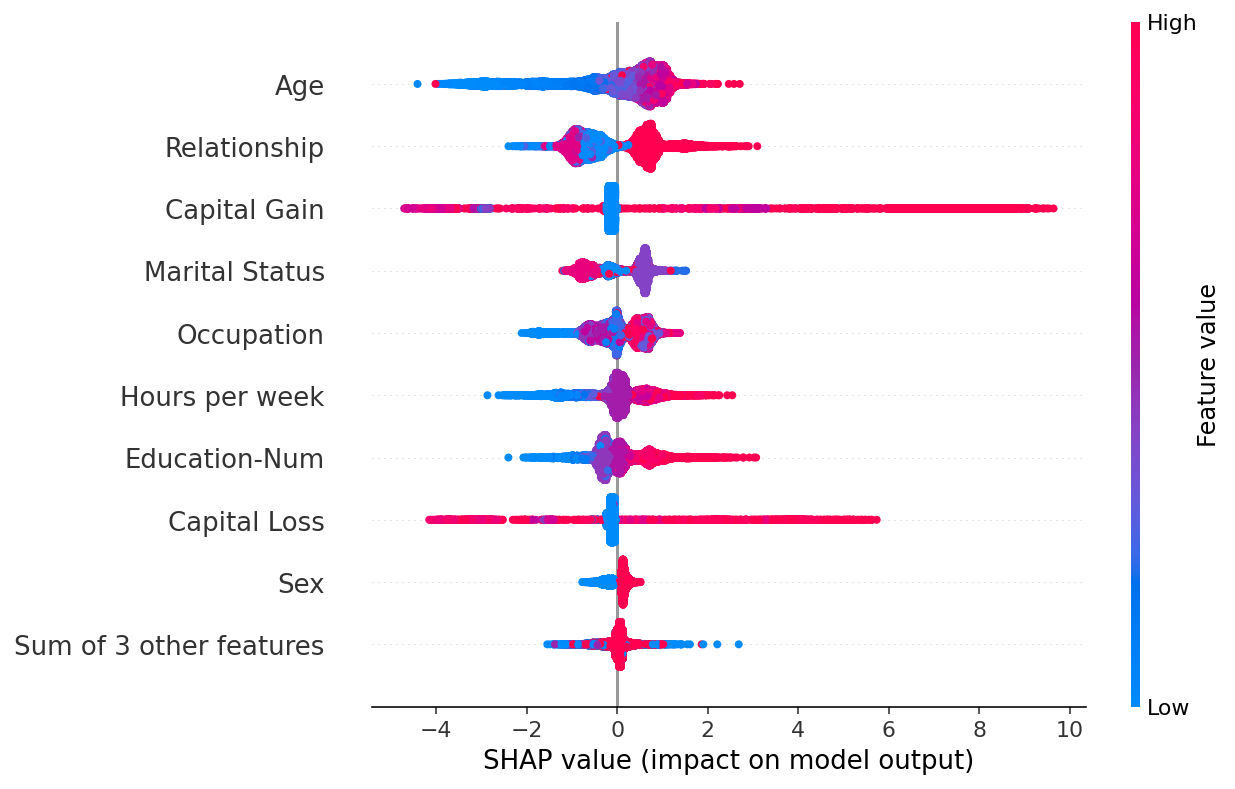
默认情况下,显示的最大特征数为 10 个,但这可以使用 max_display 参数进行调整
[3]:
shap.plots.beeswarm(shap_values, max_display=20)
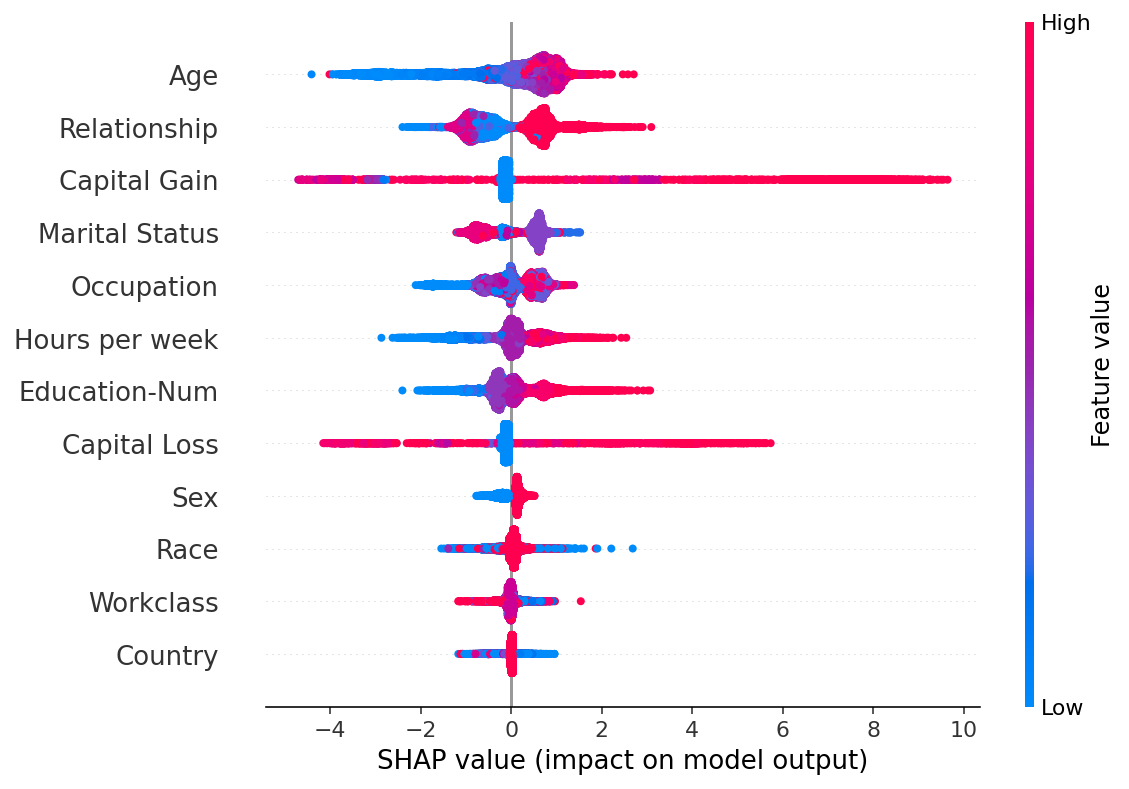
特征排序
默认情况下,特征使用 shap_values.abs.mean(0) 进行排序,这是每个特征的 SHAP 值的平均绝对值。然而,这种顺序更强调广泛的平均影响,而较少强调罕见但高幅度的影响。如果我们想找到对个人影响很大的特征,我们可以改为按最大绝对值排序
[4]:
shap.plots.beeswarm(shap_values, order=shap_values.abs.max(0))
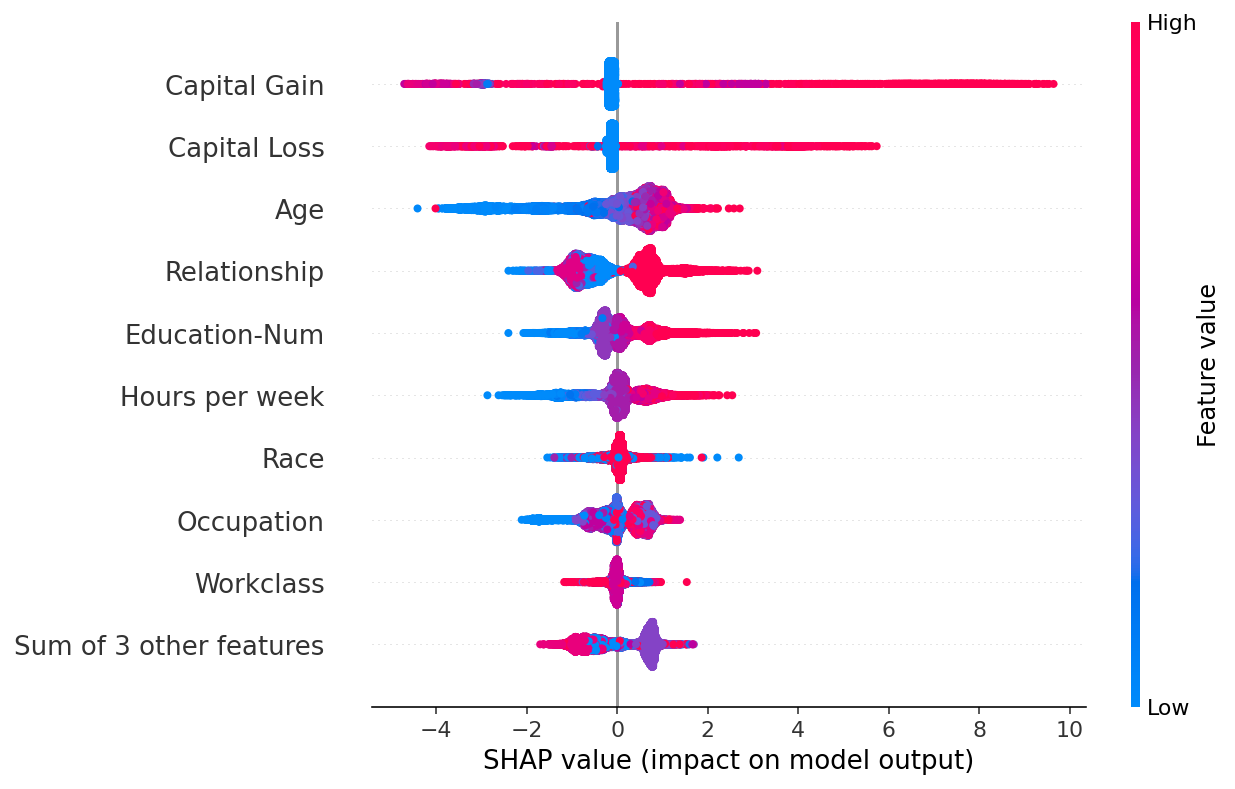
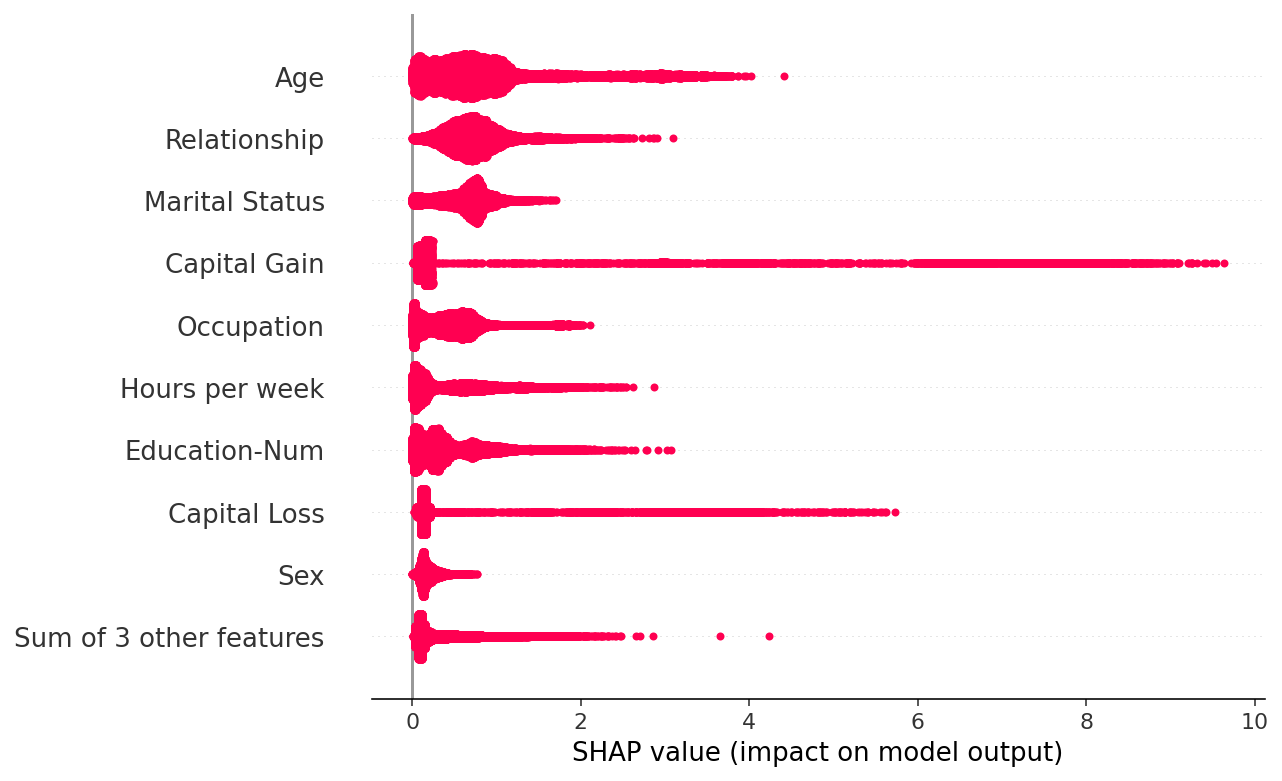
有用的变换
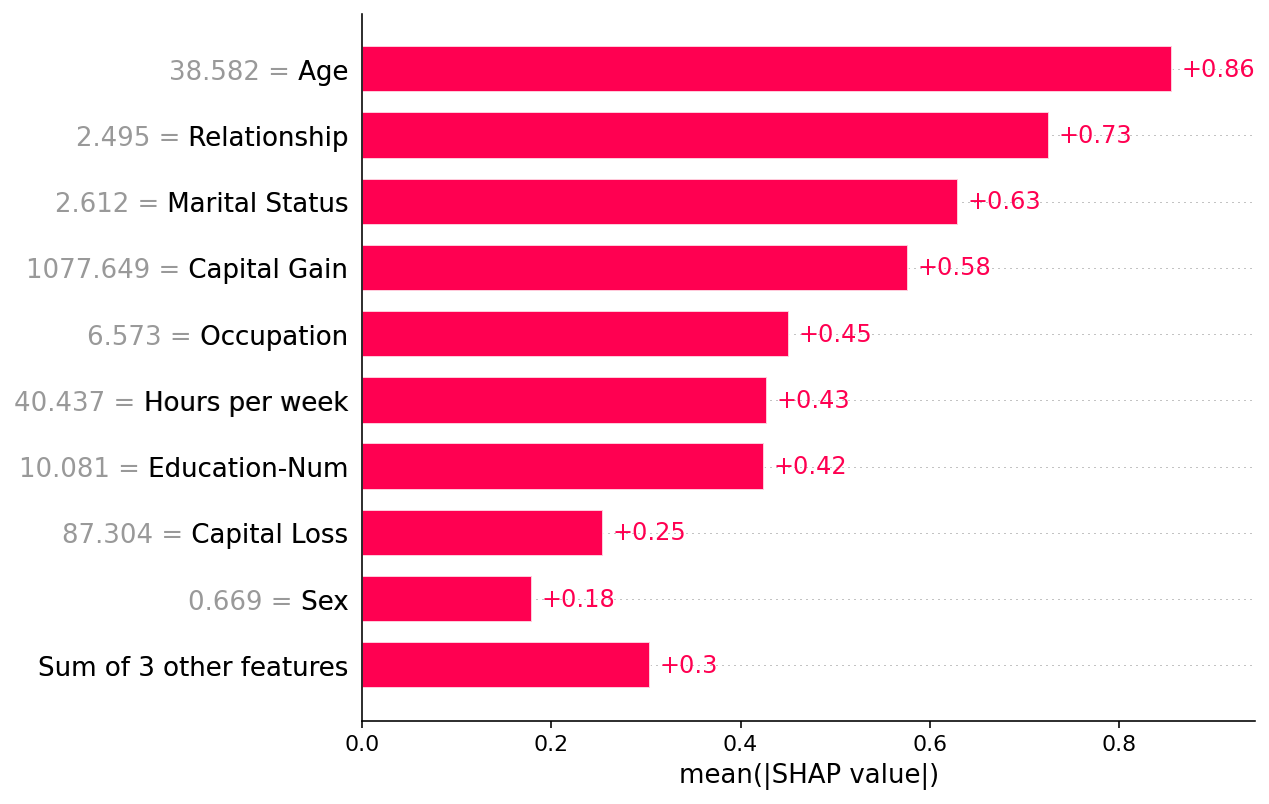
有时,在绘制 SHAP 值之前对其进行变换会很有帮助。下面我们绘制绝对值并将颜色固定为红色。这创建了一个更丰富的平行于标准 shap_values.abs.mean(0) 柱状图,因为柱状图仅绘制 beeswarm 图中点的平均值。
[5]:
shap.plots.beeswarm(shap_values.abs, color="shap_red")
[6]:
shap.plots.bar(shap_values.abs.mean(0))
自定义颜色
默认情况下,beeswarm 使用 shap.plots.colors.red_blue 颜色映射,但您可以使用 color 参数传递任何 matplotlib 颜色或颜色映射
[7]:
import matplotlib.pyplot as plt
shap.plots.beeswarm(shap_values, color=plt.get_cmap("cool"))
有更多有用的示例的想法吗?鼓励提出 pull request 来添加到此文档 notebook!