heatmap plot (热图)
本笔记本旨在演示(并因此记录)如何使用 shap.plots.heatmap 函数。它使用在经典的 UCI 成人收入数据集上训练的 XGBoost 模型(这是一个分类任务,用于预测人们在 1990 年代年收入是否超过 5 万美元)。
[3]:
import xgboost
import shap
# train XGBoost model
X, y = shap.datasets.adult()
model = xgboost.XGBClassifier(n_estimators=100, max_depth=2).fit(X, y)
# compute SHAP values
explainer = shap.Explainer(model, X)
shap_values = explainer(X[:1000])
将 SHAP 值矩阵传递给热图绘制函数会创建一个图,其中 x 轴表示实例,y 轴表示模型输入,SHAP 值编码在颜色标度上。默认情况下,样本使用 shap.order.hclust 排序,这会根据其解释相似性通过分层聚类对样本进行排序。这导致对于相同原因具有相同模型输出的样本被分组在一起(例如,在下图中的资本收益具有高影响的人)。
模型的输出显示在热图矩阵上方(以解释的 .base_value 为中心),每个模型输入的全局重要性显示为绘图右侧的条形图(默认情况下,这是 shap.order.abs.mean 总体重要性度量)。
[6]:
shap.plots.heatmap(shap_values)
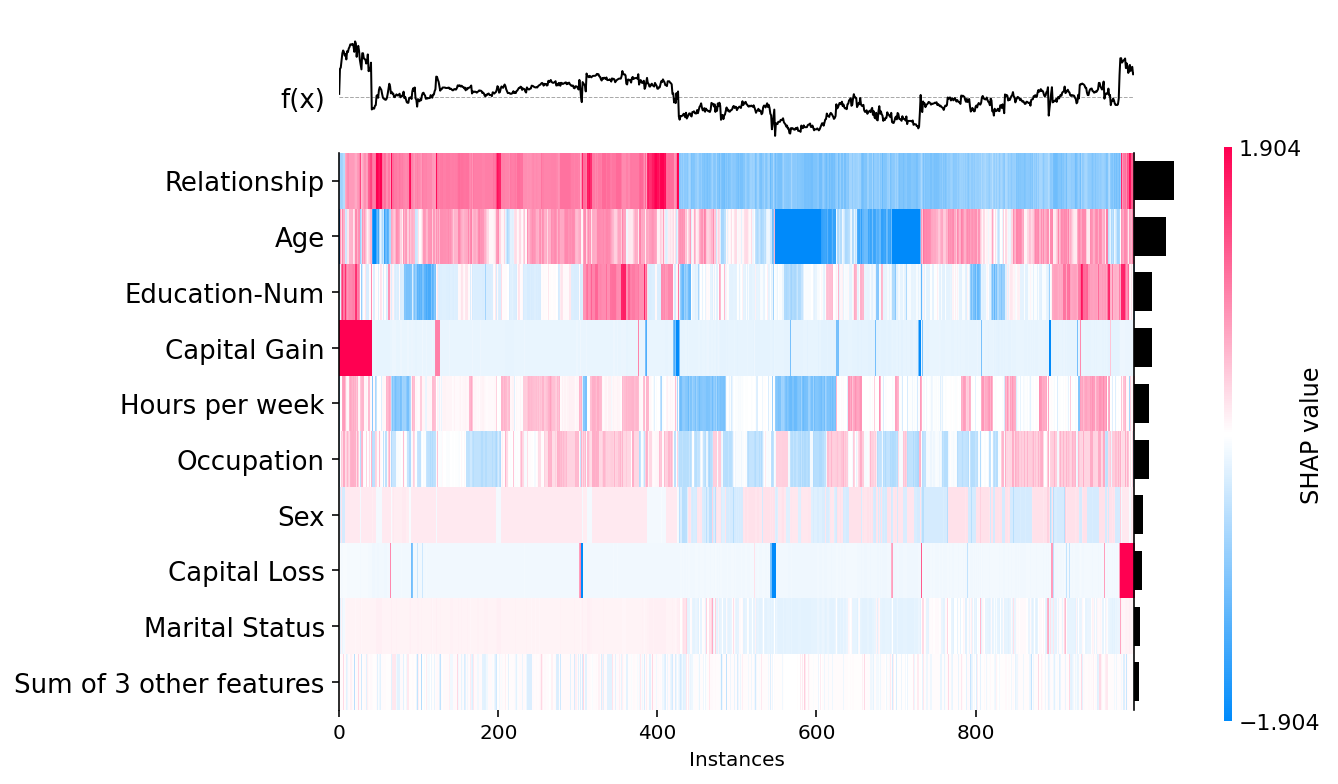
增加 max_display 参数允许显示更多特征
[3]:
shap.plots.heatmap(shap_values, max_display=12)
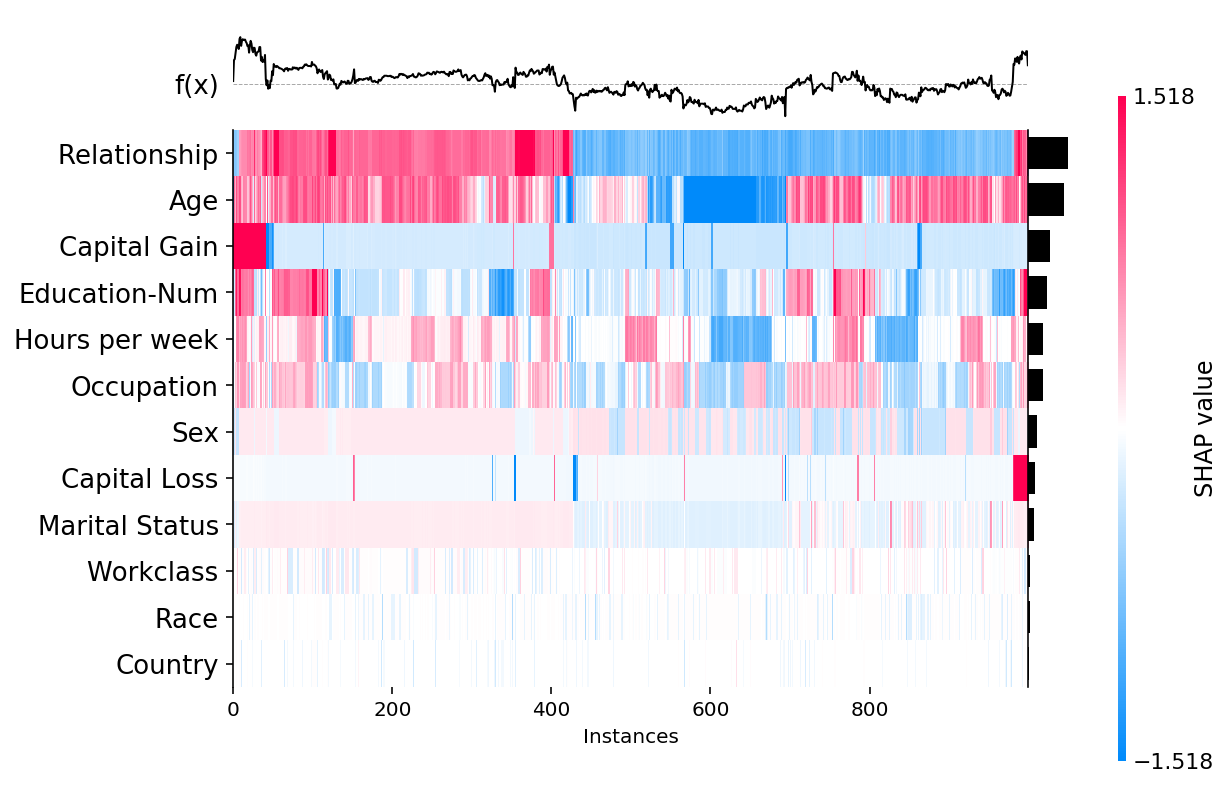
更改排序顺序和全局特征重要性值
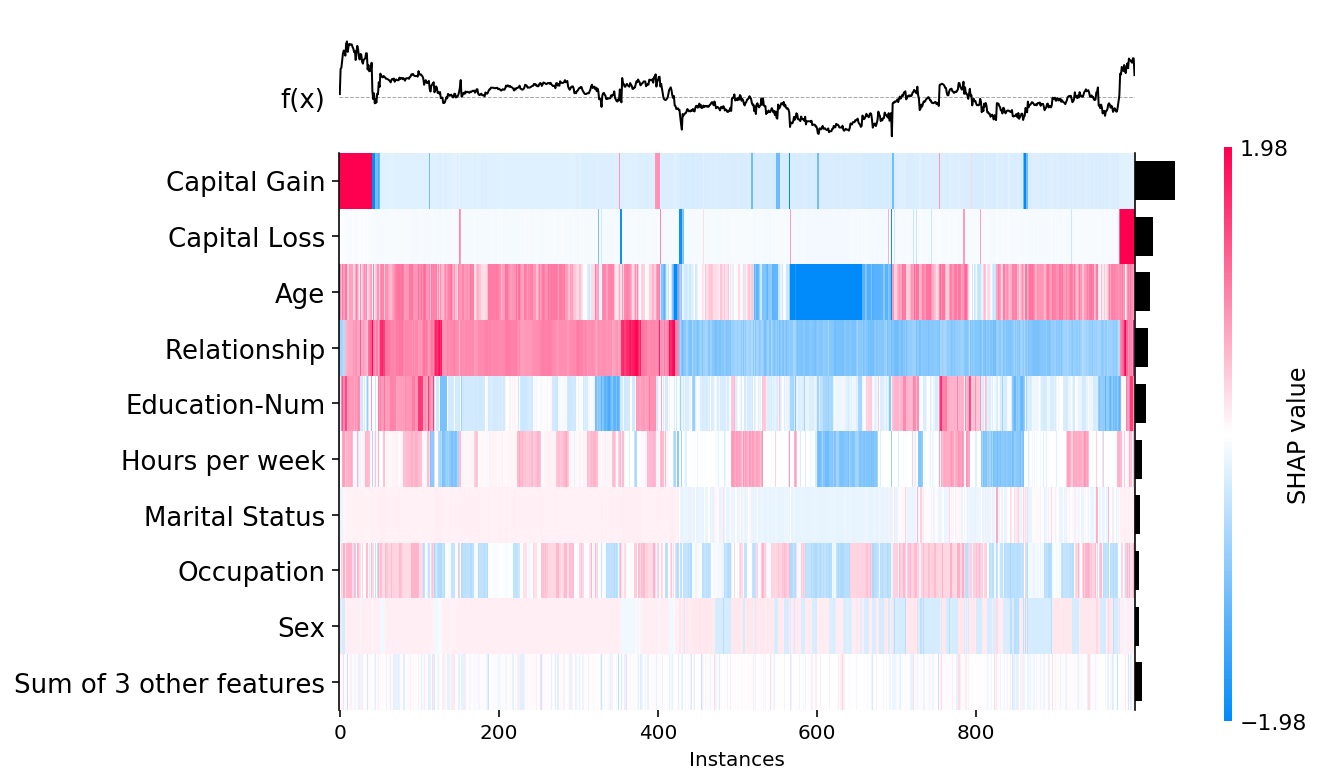
我们可以通过将一组值传递给 feature_values 参数来更改特征的总体重要性的度量方式(以及排序顺序)。默认情况下 feature_values=shap.Explanation.abs.mean(0),但在下面我们展示如何改为按特征在所有样本中的最大绝对值进行排序
[4]:
shap.plots.heatmap(shap_values, feature_values=shap_values.abs.max(0))
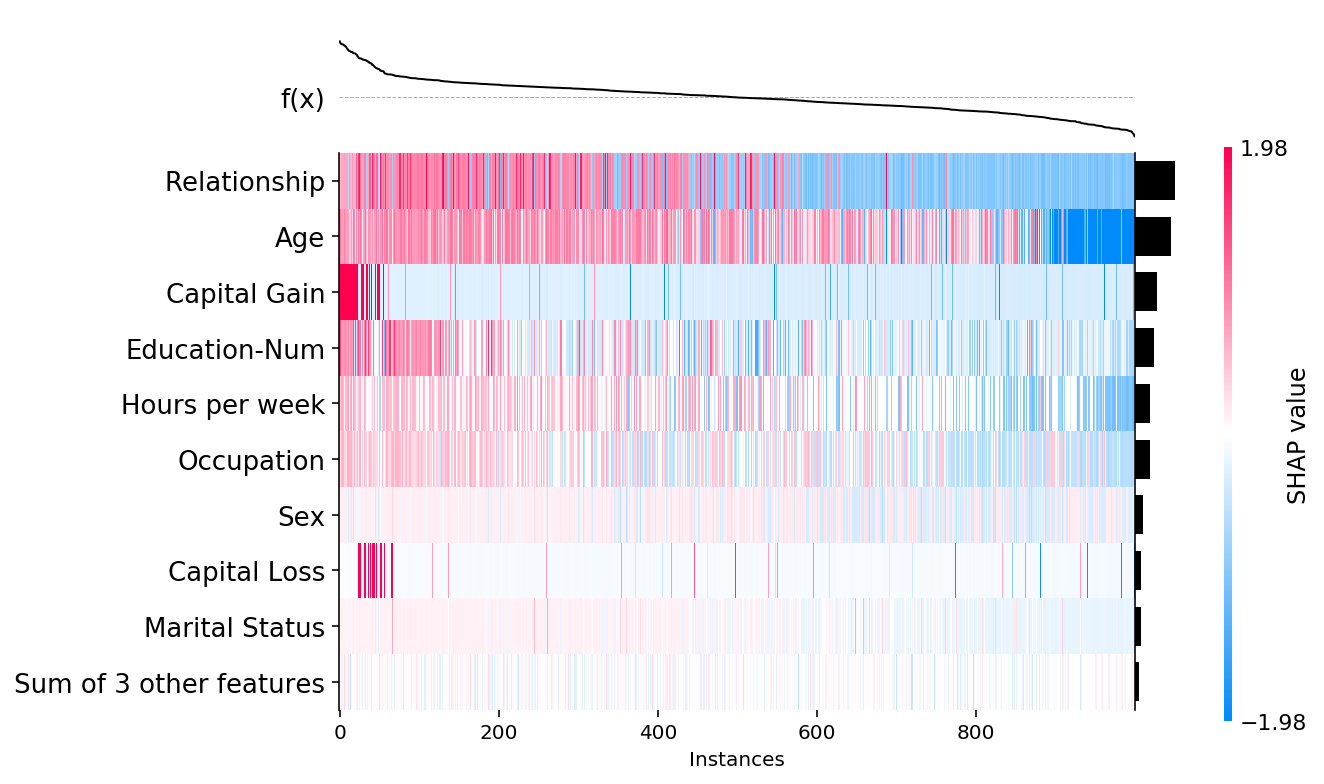
我们还可以使用 instance_order 参数控制实例的排序。默认情况下,它设置为 shap.Explanation.hclust(0) 以将具有相似解释的样本分组在一起。下面我们展示了按所有特征的 SHAP 值之和排序如何提供关于数据的补充视角
[5]:
shap.plots.heatmap(shap_values, instance_order=shap_values.sum(1))
有更多有用的示例的想法吗?欢迎提交拉取请求以添加到此文档笔记本!