waterfall 绘图
此 notebook 旨在演示(并因此记录)如何使用 shap.plots.waterfall 函数。它使用在经典的 UCI 成人收入数据集上训练的 XGBoost 模型(这是一个分类任务,用于预测人们在 90 年代是否年收入超过 5 万美元)。
[1]:
import xgboost
import shap
# train XGBoost model
X, y = shap.datasets.adult()
model = xgboost.XGBClassifier().fit(X, y)
# compute SHAP values
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
99%|===================| 32335/32561 [00:58<00:00]
瀑布图旨在显示对单个预测的解释,因此它们期望 Explanation 对象的单行作为输入。瀑布图的底部从模型输出的期望值开始,然后每一行显示每个特征的正(红色)或负(蓝色)贡献如何将值从背景数据集上的预期模型输出移动到此预测的模型输出。
下面是一个绘制第一个解释的示例。请注意,默认情况下,SHAP 根据其边际输出(在 logistic 链接函数之前)来解释 XGBoost 分类器模型。这意味着 x 轴上的单位是 log-odds 单位,因此负值意味着一个人年收入超过 5 万美元的概率小于 0.5。特征名称之前的灰色文本显示此样本中每个特征的值。
[2]:
shap.plots.waterfall(shap_values[0])

请注意,在上面的解释中,三个影响最小的特征已折叠为一个术语,这样我们在图中就不会显示超过 10 行。可以使用 max_display 参数更改默认的 10 行限制
[3]:
shap.plots.waterfall(shap_values[0], max_display=20)

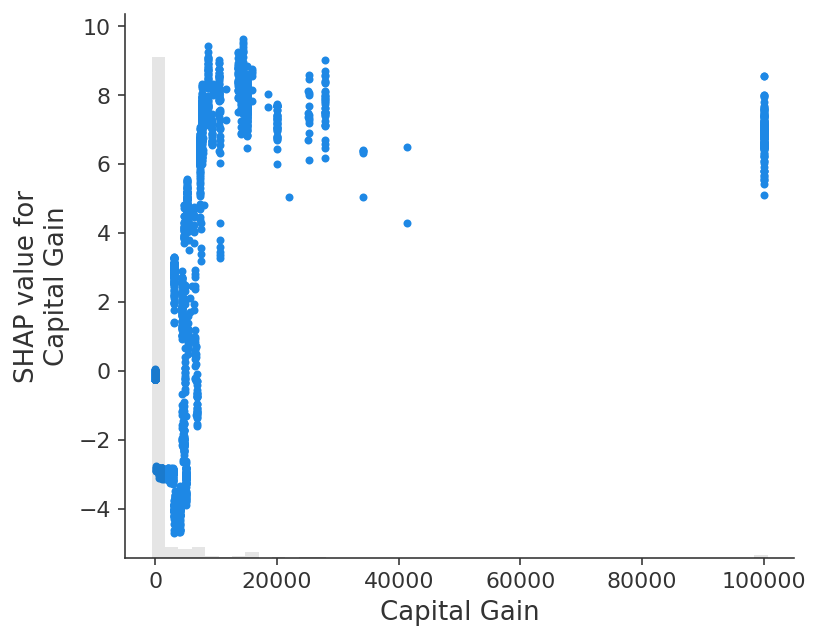
有趣的是,拥有 2,174 美元的资本收益会大大降低这个人年收入超过 5 万美元的预测概率。由于 waterfall 图仅显示单个样本的数据,因此我们无法看到改变资本收益的影响。要看到这一点,我们可以使用 scatter 图,它显示了资本收益的低值如何比没有资本收益更能负面地预测收入。为什么会发生这种情况需要更深入地研究数据,并且还应该更仔细地训练模型并使用 bootstrap 重采样来量化模型构建过程中的任何不确定性。
[4]:
shap.plots.scatter(shap_values[:, "Capital Gain"])
有更多有用的示例的想法吗? 欢迎提交 pull request 以添加到此文档 notebook!