使用 scikit-learn 进行人口普查收入分类
本示例使用来自 UCI 机器学习数据存储库的标准成年人人口普查收入数据集。我们使用 sci-kit learn 训练一个 K-近邻分类器,然后解释其预测。
[1]:
import sklearn
import shap
加载人口普查数据
[2]:
X, y = shap.datasets.adult()
X["Occupation"] *= 1000 # to show the impact of feature scale on KNN predictions
X_display, y_display = shap.datasets.adult(display=True)
X_train, X_valid, y_train, y_valid = sklearn.model_selection.train_test_split(X, y, test_size=0.2, random_state=7)
训练一个 K-近邻分类器
这里我们直接在数据上进行训练,不进行任何归一化处理。
[4]:
knn = sklearn.neighbors.KNeighborsClassifier()
knn.fit(X_train, y_train)
[4]:
KNeighborsClassifier()
解释预测
通常我们会使用 logit 链接函数,以让加性特征输入更好地映射到模型的概率输出空间,但 K-近邻(knn)可以产生无限的对数几率比,所以本例中我们不这样做。
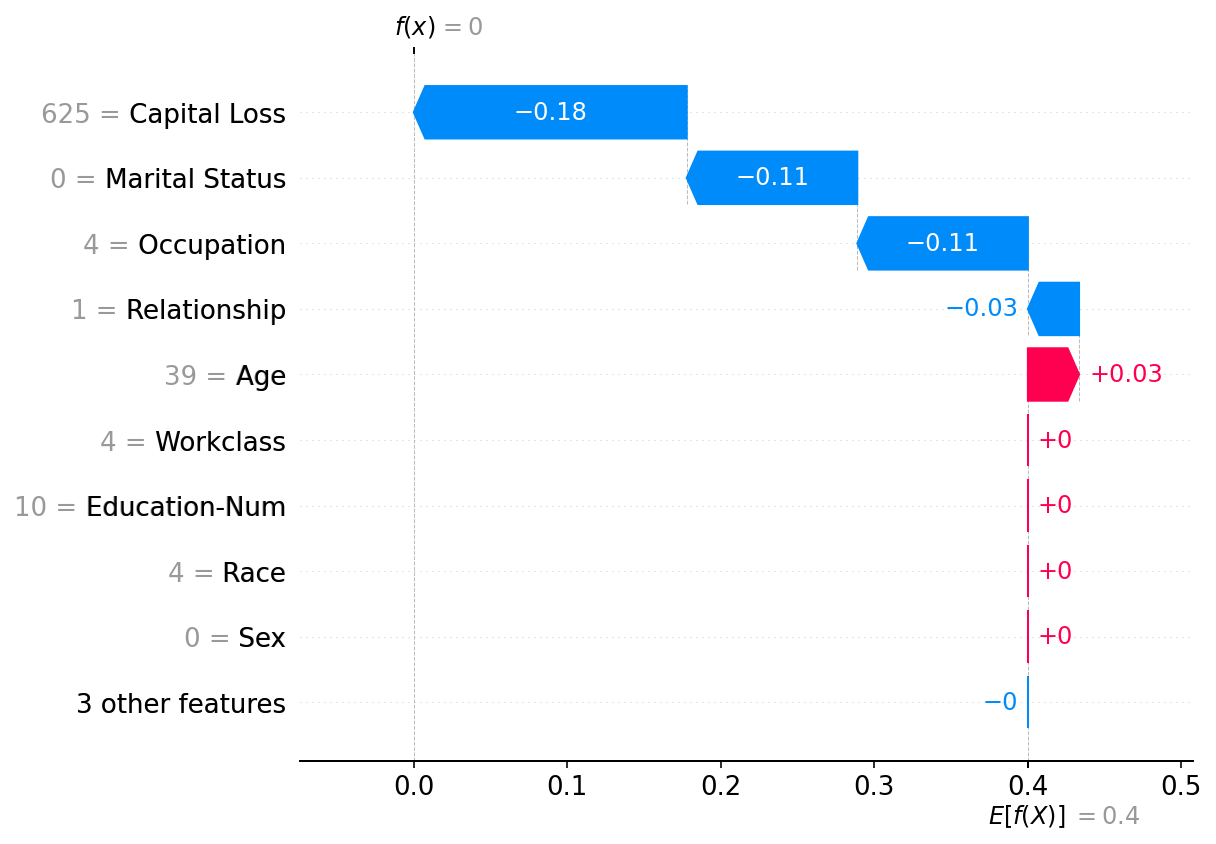
值得注意的是,在我们解释的 1000 个预测中,“职业”是主导特征。这是因为它值的变化范围比其他特征大,因此对 K-近邻计算的影响也更大。
[5]:
def f(x):
return knn.predict_proba(x)[:, 1]
med = X_train.median().values.reshape((1, X_train.shape[1]))
explainer = shap.Explainer(f, med)
shap_values = explainer(X_valid.iloc[0:1000, :])
Permutation explainer: 1001it [00:25, 38.69it/s]
[5]:
shap.plots.waterfall(shap_values[0])
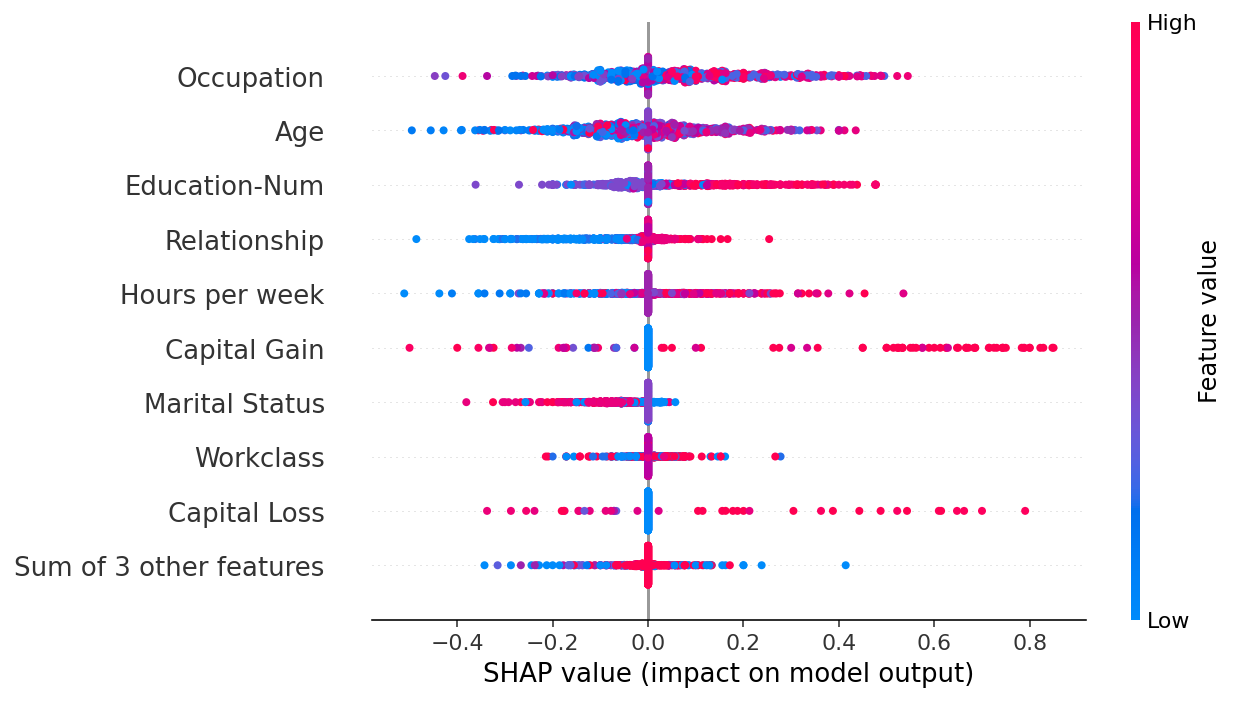
摘要蜂群图是查看所有特征在整个数据集上相对影响的更好方式。特征按其在所有样本中的 SHAP 值绝对值之和进行排序。
[7]:
shap.plots.beeswarm(shap_values)
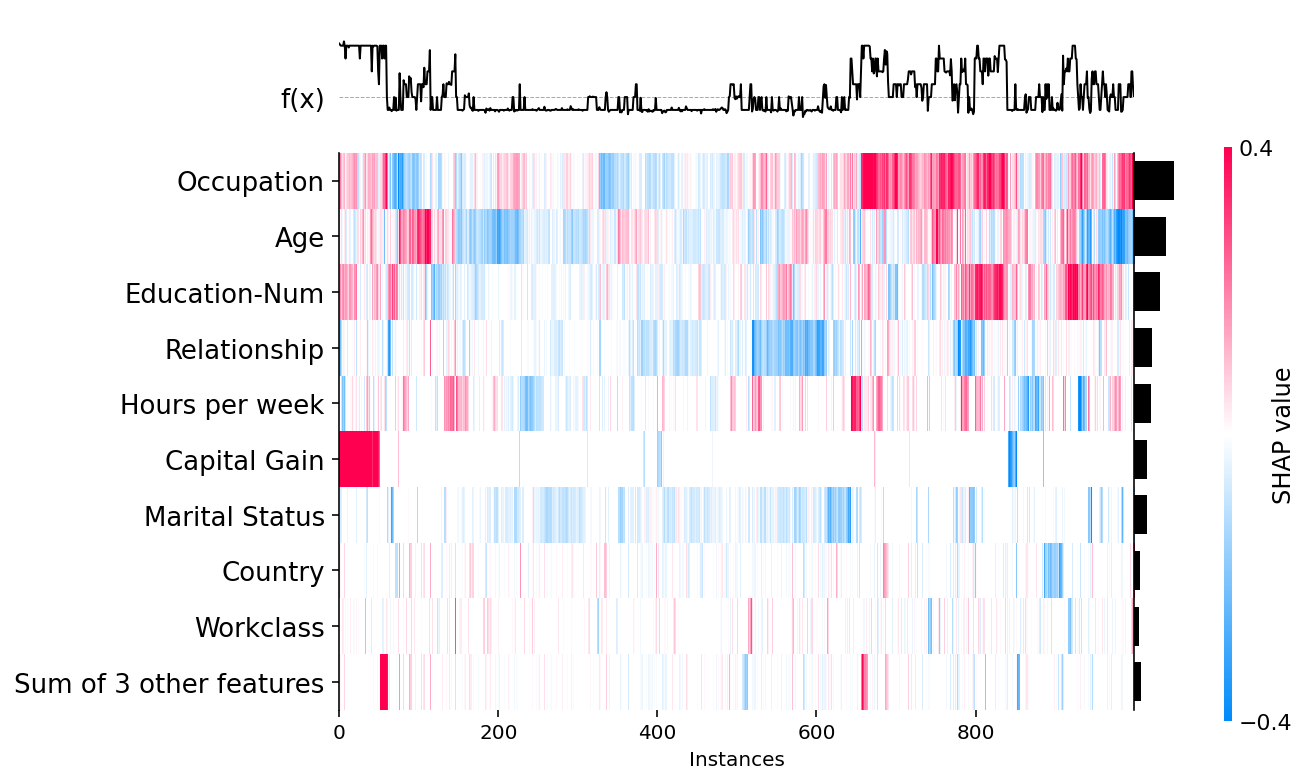
热力图提供了对模型行为的另一种全局视角,这次侧重于人口子群体。
[8]:
shap.plots.heatmap(shap_values)
在训练模型前对数据进行归一化
这里我们使用标准化后的数据重新训练一个 KNN 模型。
[9]:
# normalize data
dtypes = list(zip(X.dtypes.index, map(str, X.dtypes)))
X_train_norm = X_train.copy()
X_valid_norm = X_valid.copy()
for k, dtype in dtypes:
m = X_train[k].mean()
s = X_train[k].std()
X_train_norm[k] -= m
X_train_norm[k] /= s
X_valid_norm[k] -= m
X_valid_norm[k] /= s
[10]:
knn_norm = sklearn.neighbors.KNeighborsClassifier()
knn_norm.fit(X_train_norm, y_train)
[10]:
KNeighborsClassifier()
解释预测
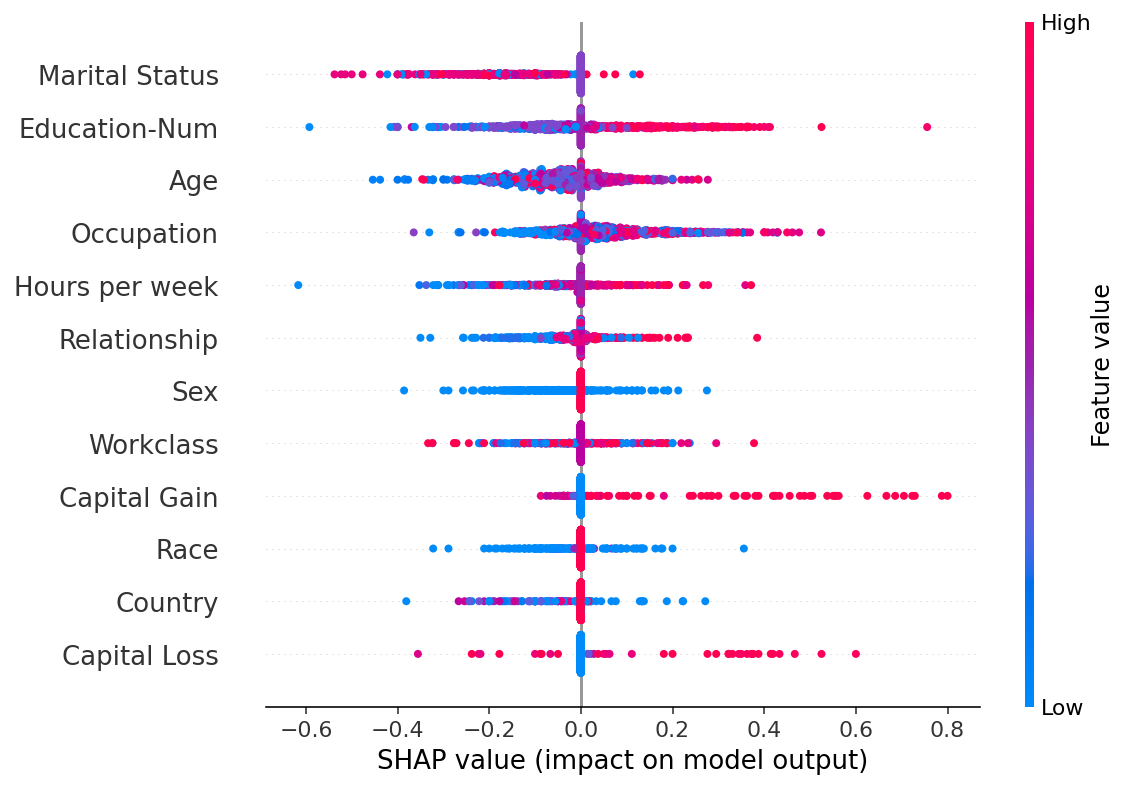
当我们解释新的 KNN 模型的预测时,我们发现“职业”不再是主导特征,取而代之的是更具预测性的特征,如“婚姻状况”,它驱动了大多数预测。这是一个简单的例子,说明了解释模型为何做出预测可以揭示训练过程中的问题。
[11]:
def f(x):
return knn_norm.predict_proba(x)[:, 1]
med = X_train_norm.median().values.reshape((1, X_train_norm.shape[1]))
explainer = shap.Explainer(f, med)
shap_values_norm = explainer(X_valid_norm.iloc[0:1000, :])
Permutation explainer: 1001it [01:26, 11.55it/s]
通过摘要图,我们看到“婚姻状况”平均而言是最重要的,但其他特征(如“资本收益”)可能对特定个体有更大的影响。
[12]:
shap.summary_plot(shap_values_norm, X_valid.iloc[0:1000, :])
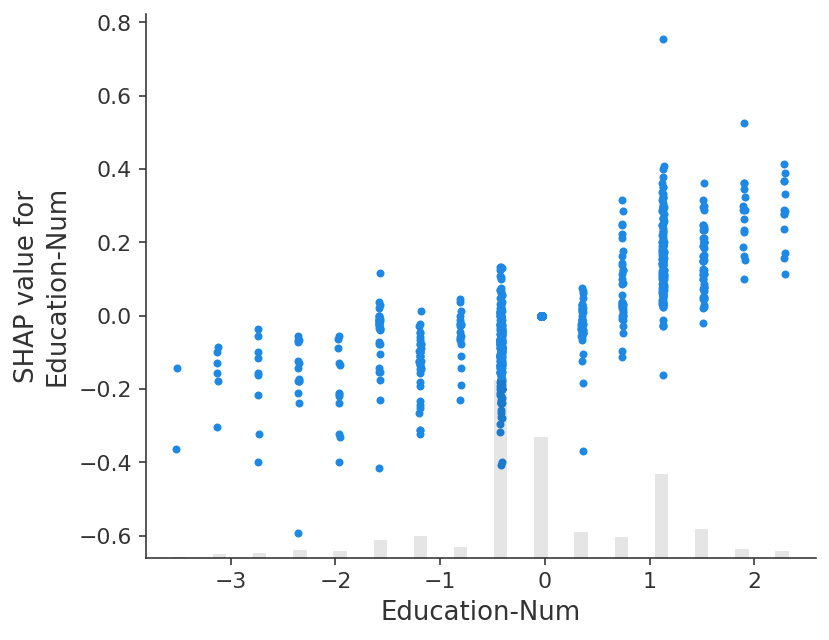
依赖散点图显示了受教育年限的增加如何提高了年收入超过 5 万美元的几率。
[14]:
shap.plots.scatter(shap_values_norm[:, "Education-Num"])
对更有帮助的示例有什么想法吗?我们鼓励您通过拉取请求(Pull Request)来为本文档笔记本添砖加瓦!