使用 LightGBM 进行人口普查收入分类
本笔记本演示了如何使用 LightGBM 预测个人年收入超过 5 万美元的可能性。它使用标准的 UCI Adult 收入数据集。要下载此笔记本的副本,请访问 github。
梯度提升机方法(如 LightGBM)对于使用多种模态的表格样式输入数据的此类预测问题是最先进的。Tree SHAP (arXiv 论文) 允许精确计算树集成方法的 SHAP 值,并已直接集成到 C++ LightGBM 代码库中。这允许快速精确计算 SHAP 值,而无需采样且无需提供背景数据集(因为背景是从树的覆盖率推断出来的)。
在此,我们演示如何使用 SHAP 值来理解 LightGBM 模型预测。
[1]:
import lightgbm as lgb
from sklearn.model_selection import train_test_split
import shap
# print the JS visualization code to the notebook
shap.initjs()

加载数据集
[2]:
X, y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)
# create a train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
d_train = lgb.Dataset(X_train, label=y_train)
d_test = lgb.Dataset(X_test, label=y_test)
训练模型
[3]:
params = {
"max_bin": 512,
"learning_rate": 0.05,
"boosting_type": "gbdt",
"objective": "binary",
"metric": "binary_logloss",
"num_leaves": 10,
"verbose": -1,
"min_data": 100,
"boost_from_average": True,
"early_stopping_round": 50,
}
model = lgb.train(
params,
d_train,
10000,
valid_sets=[d_test],
)
解释预测
在此,我们使用集成到 LightGBM 中的 Tree SHAP 实现来解释整个数据集(32561 个样本)。Tree SHAP 的 LightGBM 实现是从 shap.TreeExplainer.shap_values 方法中调用的。
[4]:
explainer = shap.TreeExplainer(model)
shap_values = explainer(X)
可视化单个预测
我们可以可视化特定个体(第一个)的不同特征的 SHAP 值
[5]:
shap.force_plot(explainer.expected_value, shap_values.values[0, :], X_display.iloc[0, :])
[5]:
您是否在本笔记本中运行了 `initjs()`?如果此笔记本来自其他用户,您还必须信任此笔记本(文件 -> 信任笔记本)。如果您在 github 上查看此笔记本,则 Javascript 已被剥离以确保安全。如果您使用的是 JupyterLab,则此错误是因为尚未编写 JupyterLab 扩展。
可视化多个预测
为了使浏览器保持良好状态,我们仅可视化 1,000 个个体。
[6]:
shap.force_plot(explainer.expected_value, shap_values.values[:1000, :], X_display.iloc[:1000, :])
[6]:
您是否在本笔记本中运行了 `initjs()`?如果此笔记本来自其他用户,您还必须信任此笔记本(文件 -> 信任笔记本)。如果您在 github 上查看此笔记本,则 Javascript 已被剥离以确保安全。如果您使用的是 JupyterLab,则此错误是因为尚未编写 JupyterLab 扩展。
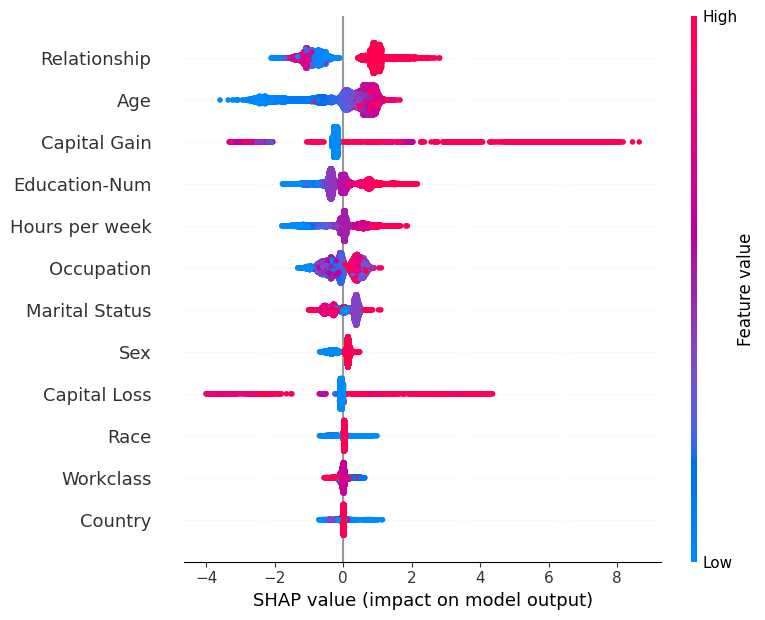
SHAP 汇总图
我们没有使用典型的特征重要性条形图,而是使用每个特征的 SHAP 值的密度散点图来识别每个特征对验证数据集中个体的模型输出的影响程度。特征按所有样本的 SHAP 值大小的总和排序。有趣的是,关系特征比资本收益特征具有更大的模型总影响,但对于那些资本收益重要的样本,它比年龄具有更大的影响。换句话说,资本收益对少数预测产生很大影响,而年龄对所有预测产生较小影响。
请注意,当散点不适合在一条线上时,它们会堆积起来以显示密度,并且每个点的颜色代表该个体的特征值。
[7]:
shap.summary_plot(shap_values, X)
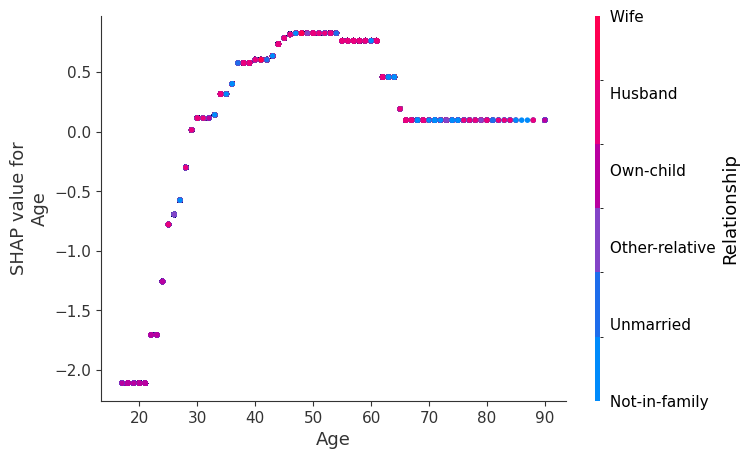
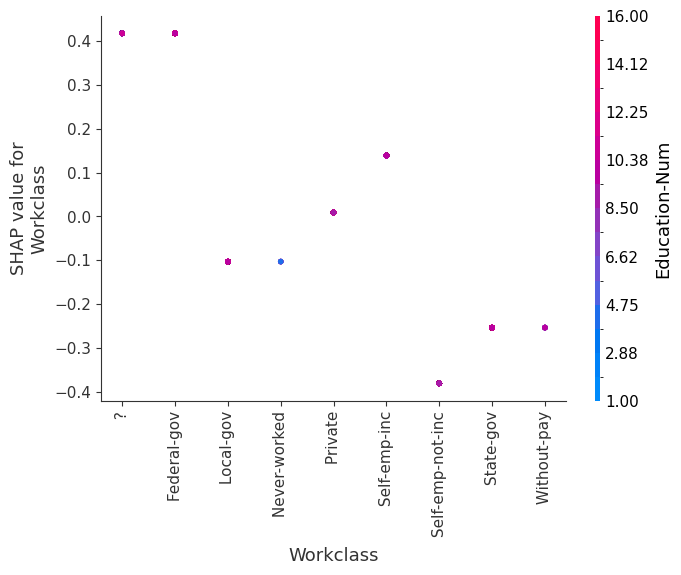
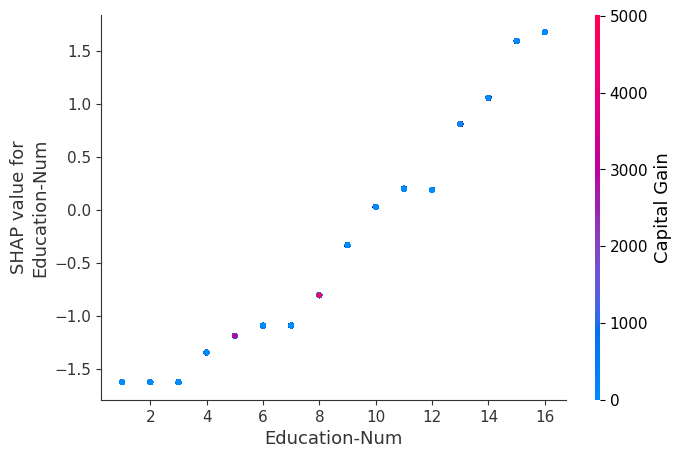
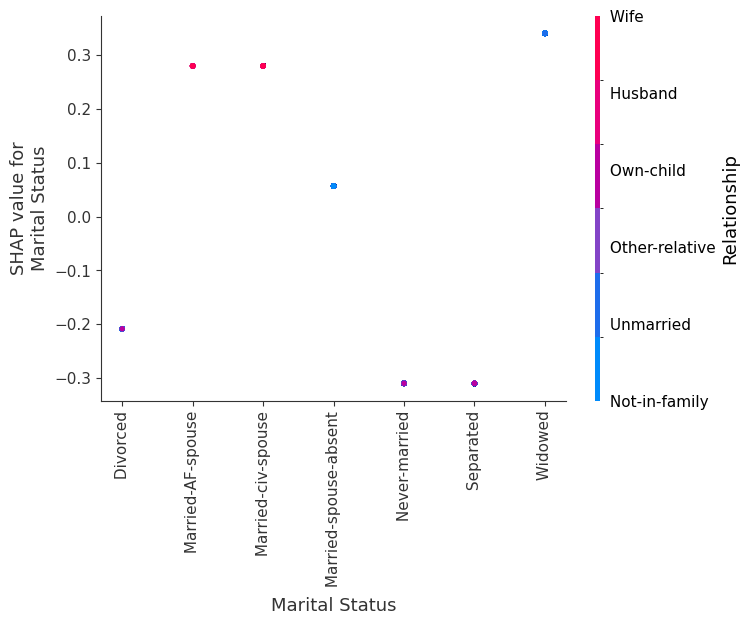
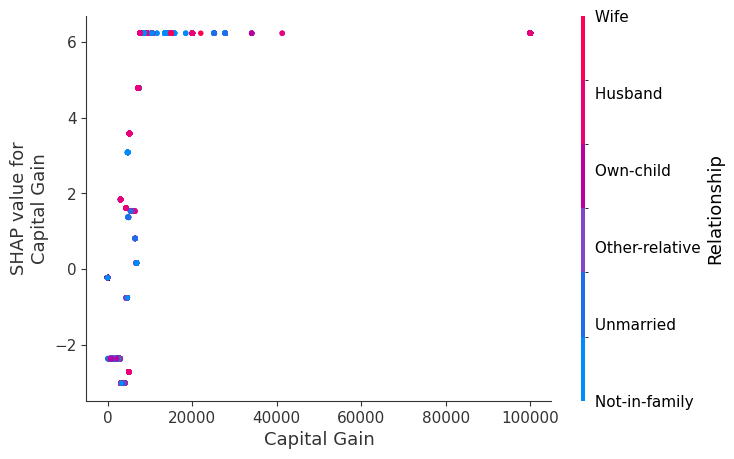
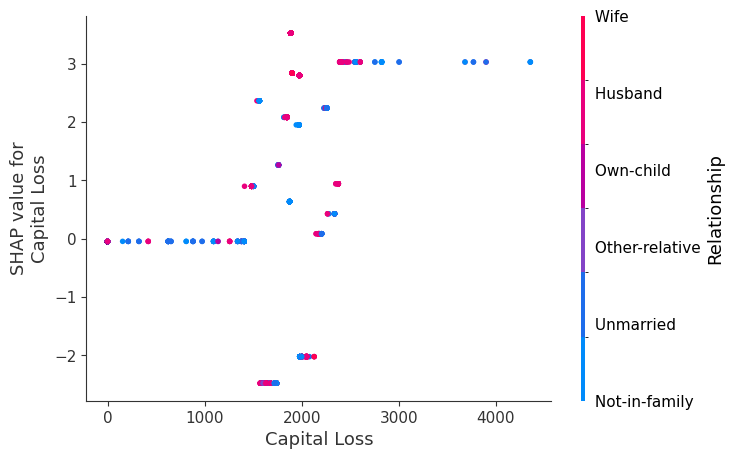
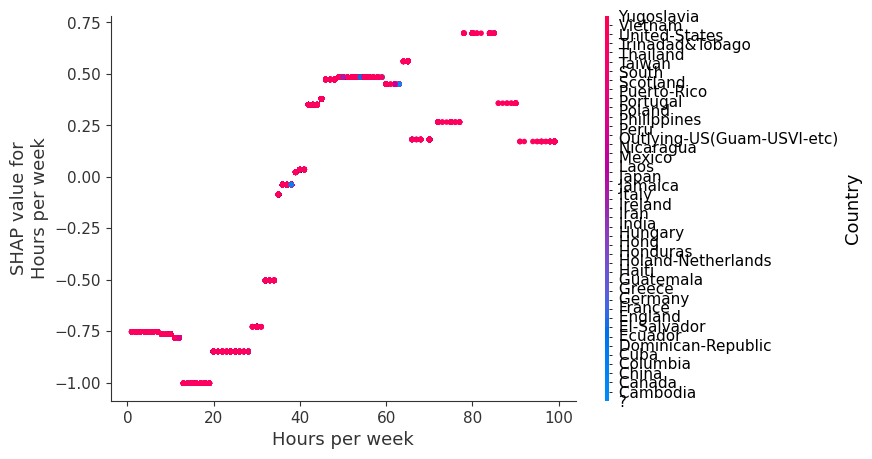
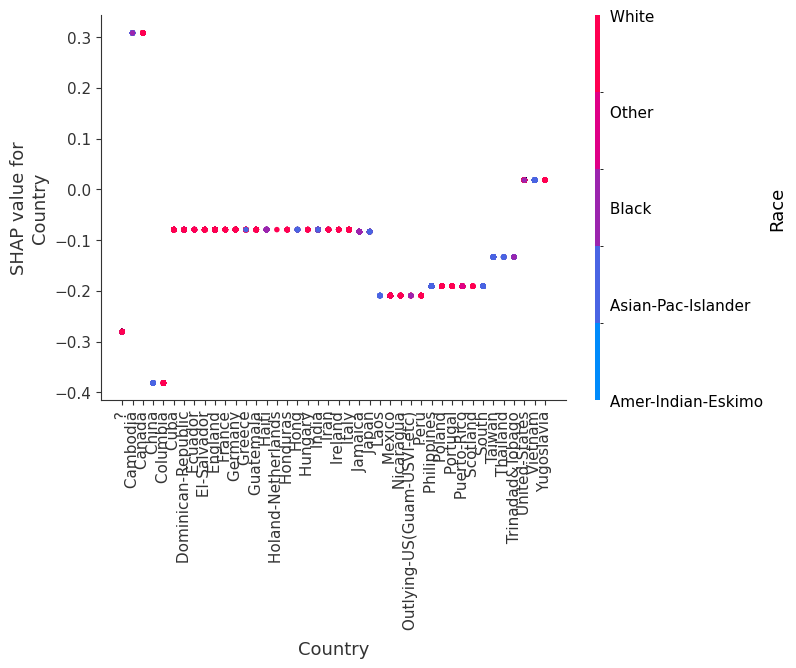
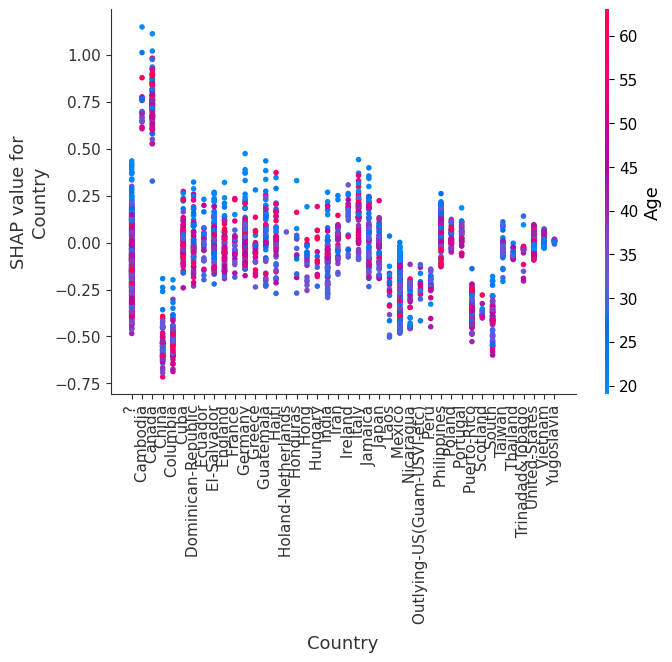
SHAP 依赖图
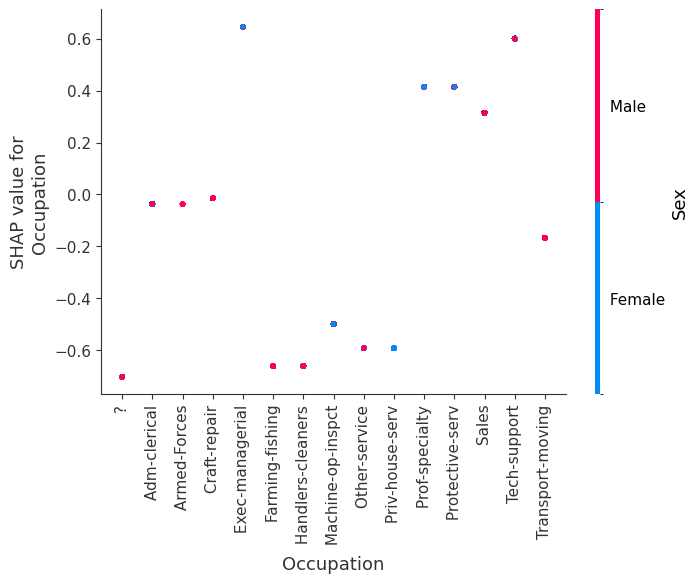
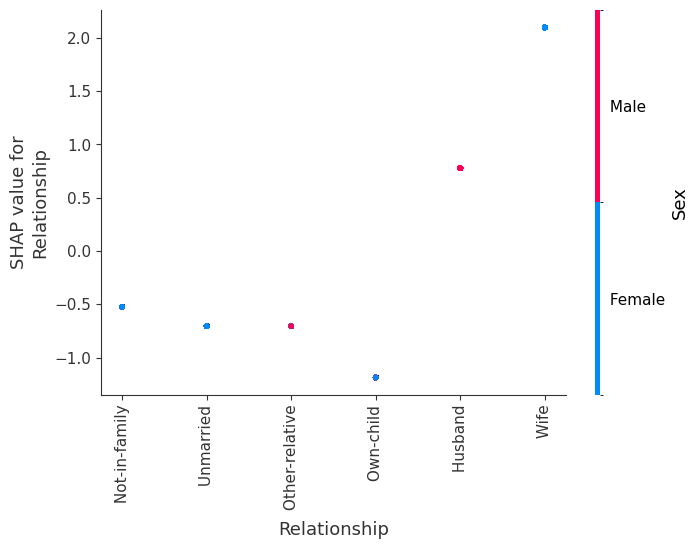
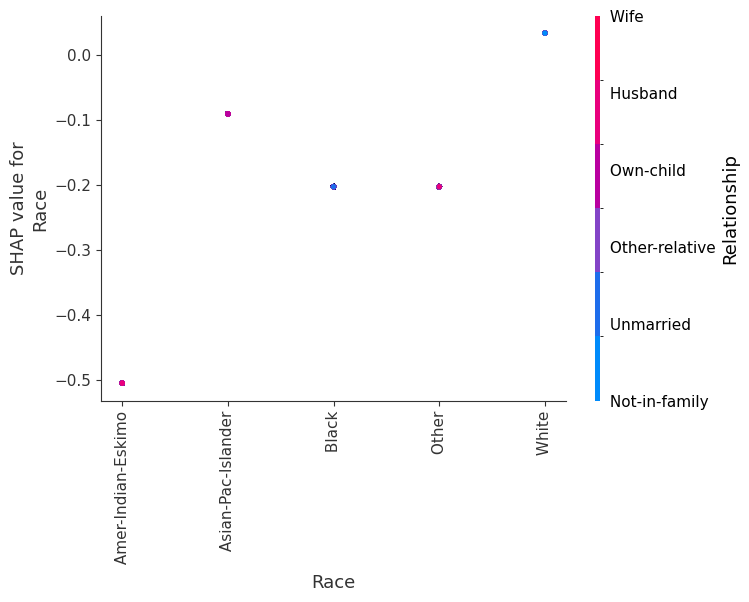
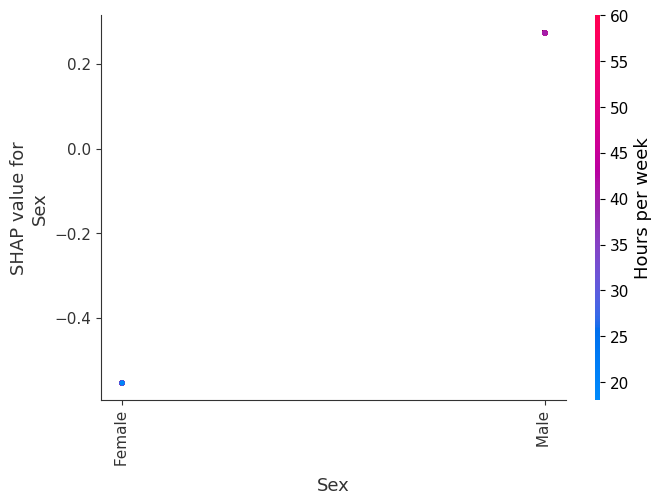
SHAP 依赖图显示单个特征在整个数据集上的影响。它们绘制了许多样本中特征的值与该特征的 SHAP 值。SHAP 依赖图类似于部分依赖图,但考虑了特征中存在的交互效应,并且仅在数据支持的输入空间区域中定义。单个特征值的 SHAP 值的垂直分散是由交互效应驱动的,并且选择另一个特征进行着色以突出可能的交互。
[8]:
for name in X_train.columns:
shap.dependence_plot(name, shap_values.values, X, display_features=X_display)
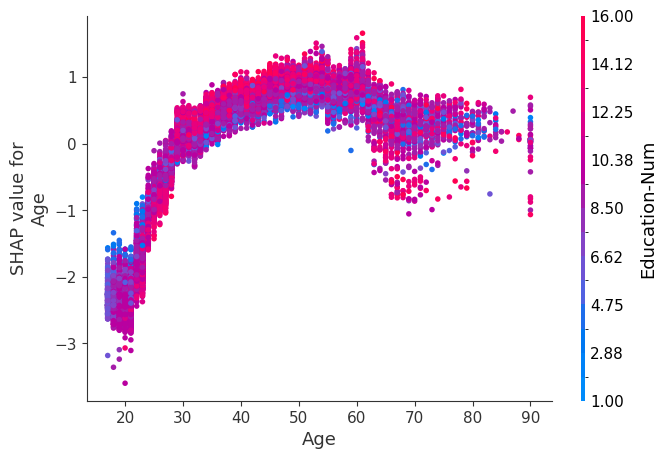
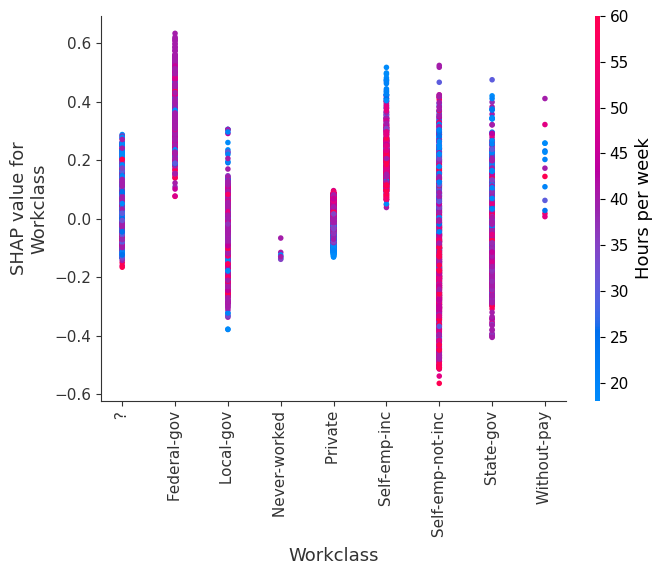
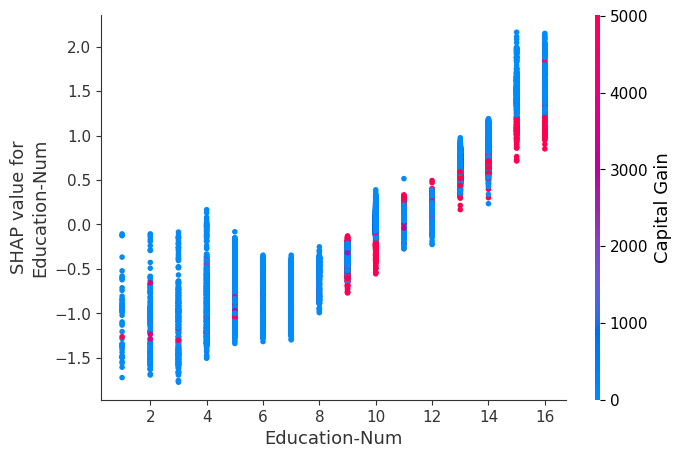
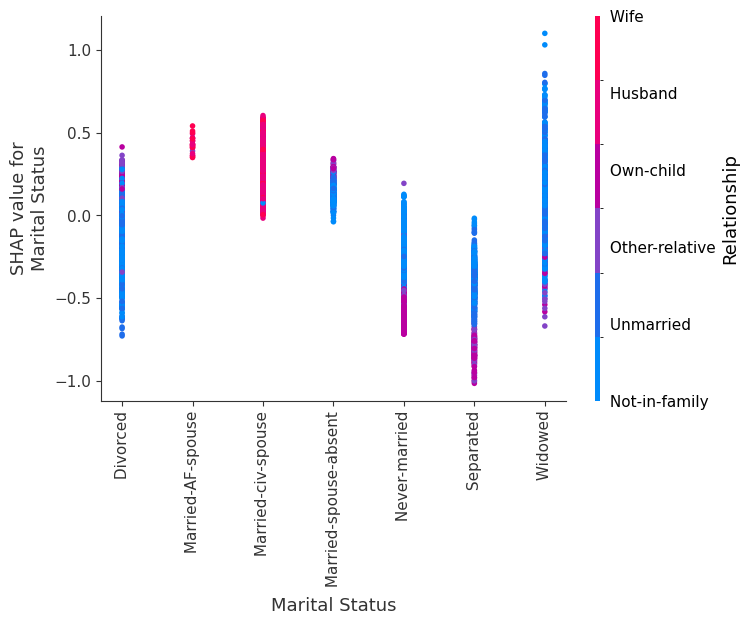
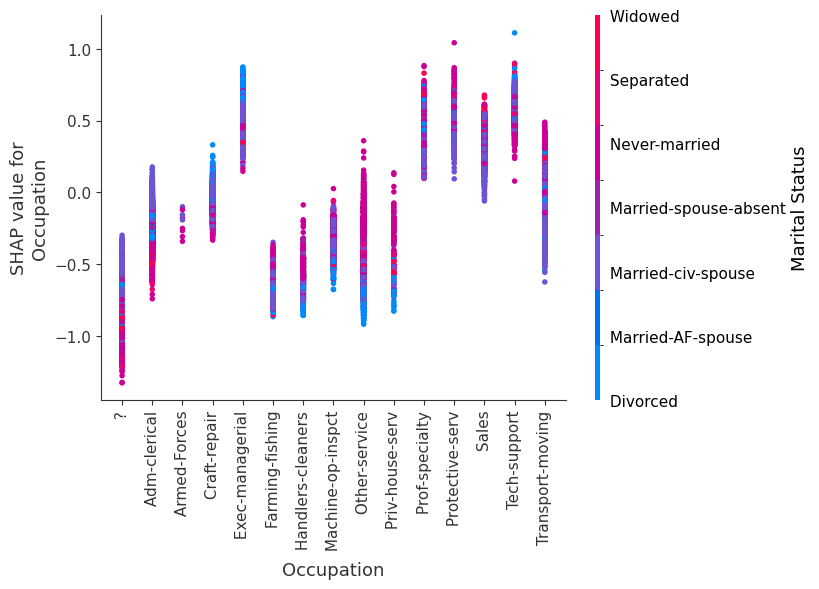
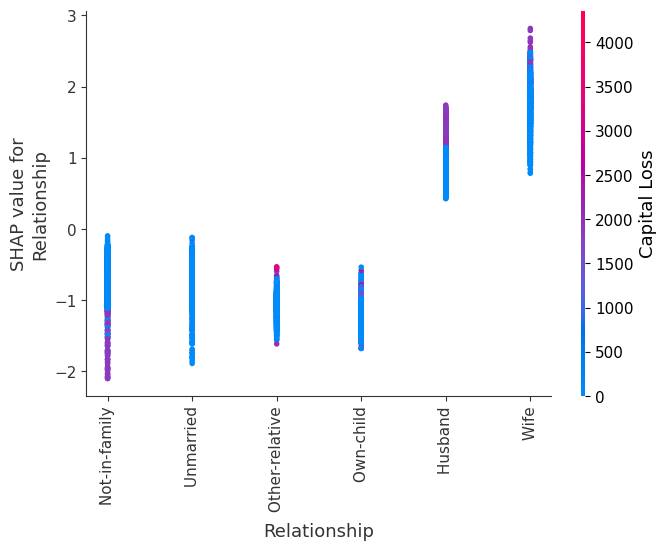
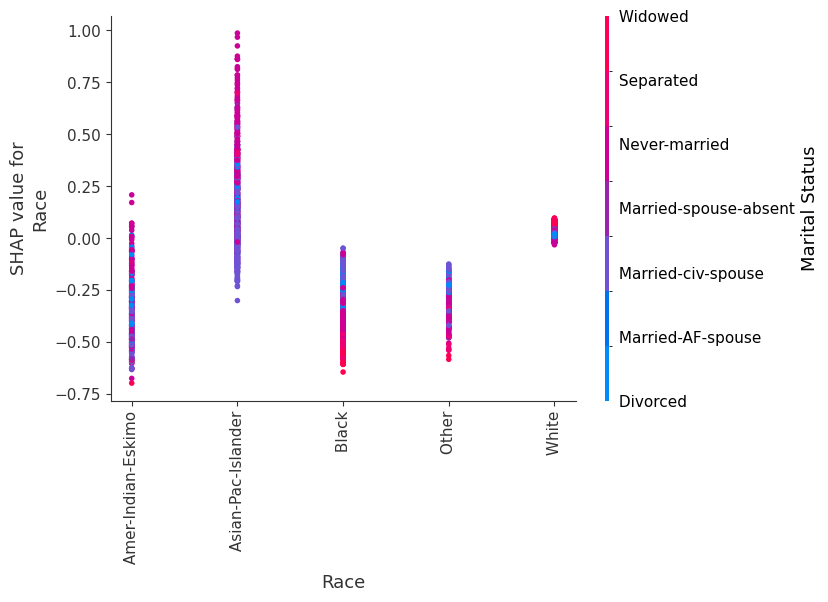
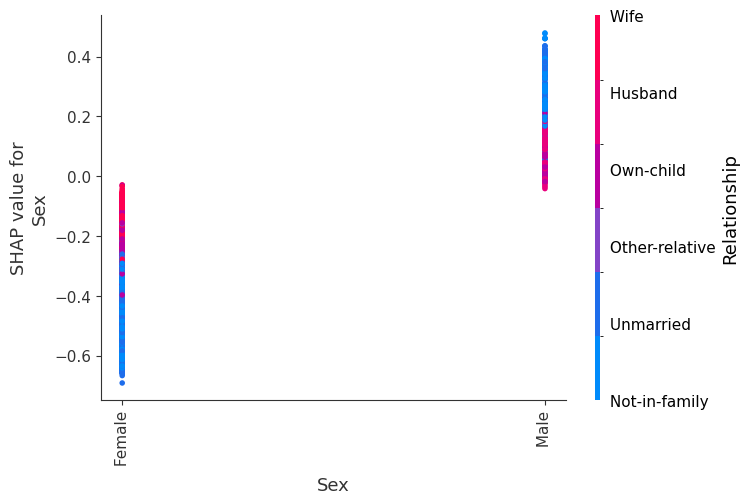
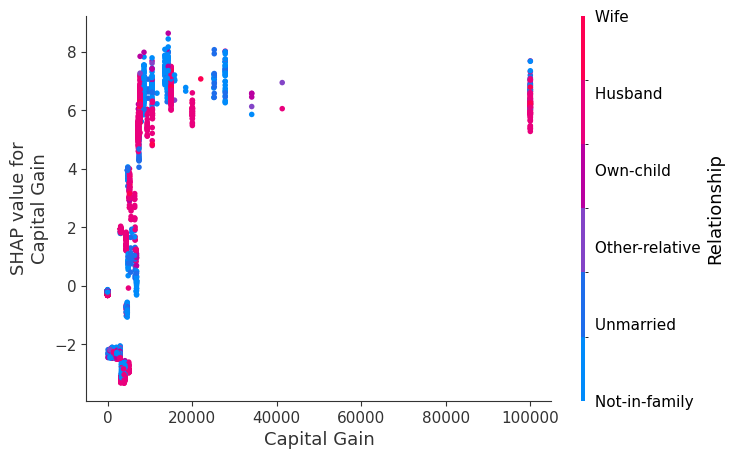
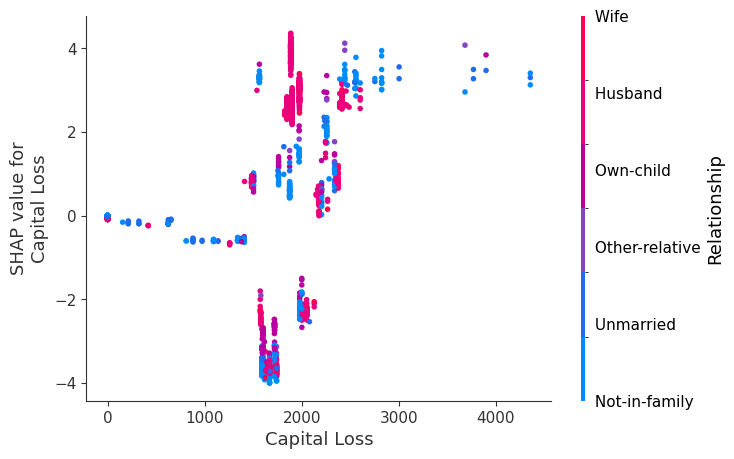
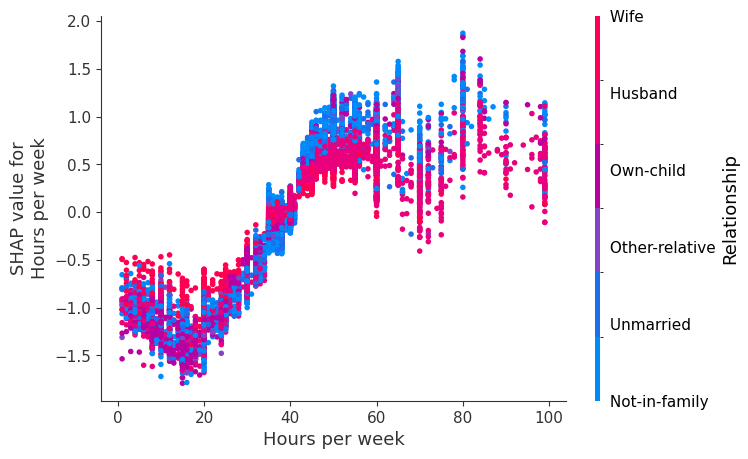
训练一个模型,每棵树只有两个叶子,因此特征之间没有交互项
强制模型没有交互项意味着特征对结果的影响不取决于任何其他特征的值。这在下面的 SHAP 依赖图中反映为没有垂直分散。垂直分散反映了单个特征值对模型输出可能具有不同的影响,具体取决于个体存在的其他特征的上下文。但是,对于没有交互项的模型,无论个体可能具有哪些其他属性,特征始终具有相同的影响。
SHAP 依赖图优于传统部分依赖图的优点之一是它能够区分具有和不具有交互项的模型。换句话说,SHAP 依赖图通过给定特征值处散点图的垂直方差,提供了交互项大小的概念。
[9]:
params = {
"max_bin": 512,
"learning_rate": 0.1,
"boosting_type": "gbdt",
"objective": "binary",
"metric": "binary_logloss",
"num_leaves": 2,
"verbose": -1,
"min_data": 100,
"boost_from_average": True,
"early_stopping_round": 50,
}
model_ind = lgb.train(
params,
d_train,
20000,
valid_sets=[d_test],
)
[10]:
explainer = shap.TreeExplainer(model_ind)
shap_values_ind = explainer(X)
请注意,下面的交互颜色条对于此模型没有意义,因为它没有交互。
[11]:
for name in X_train.columns:
shap.dependence_plot(name, shap_values_ind.values, X, display_features=X_display)