散点密度图 vs. 小提琴图
此笔记本提供多个示例来比较 summary_plot 的点密度图和小提琴图选项。
[1]:
import xgboost
import shap
# train xgboost model on diabetes data:
X, y = shap.datasets.diabetes()
bst = xgboost.train({"learning_rate": 0.01}, xgboost.DMatrix(X, label=y), 100)
# explain the model's prediction using SHAP values on the first 1000 training data samples
shap_values = shap.TreeExplainer(bst).shap_values(X)
分层小提琴图
在没有颜色时,此图可以简单地将每个变量的重要性分布显示为标准小提琴图。
[2]:
shap.summary_plot(shap_values[:1000, :], X.iloc[:1000, :], plot_type="layered_violin", color="#cccccc")
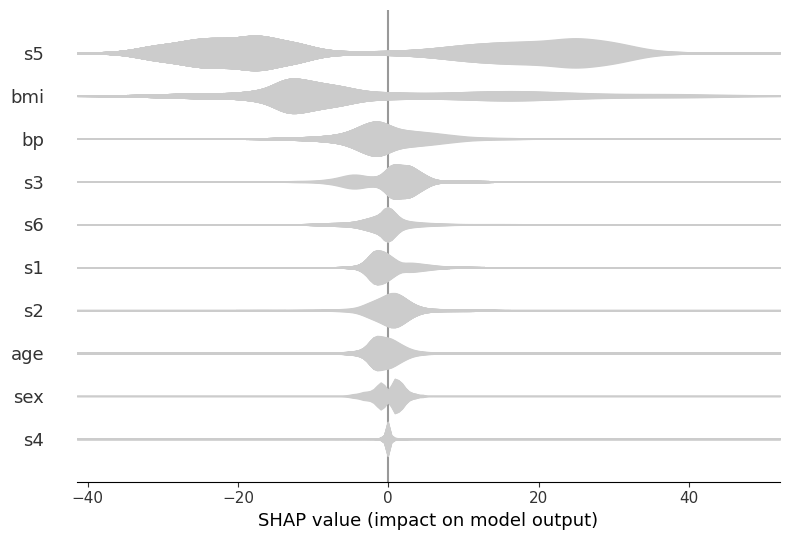
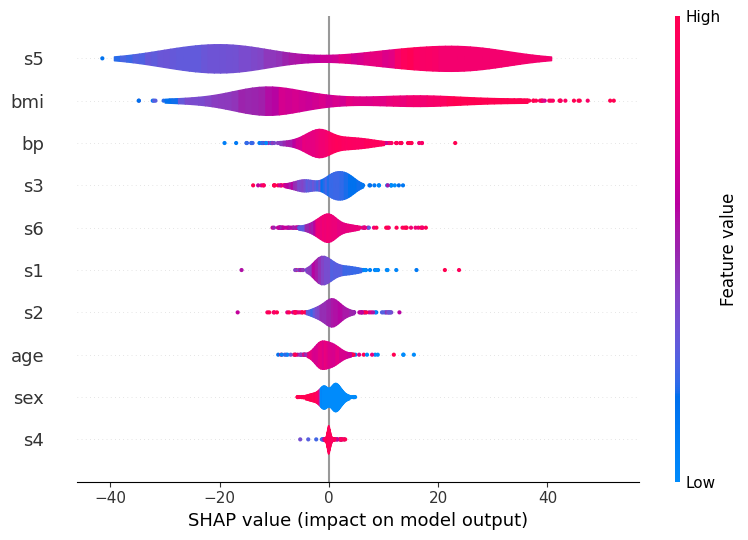
例如,在上面,我们可以看到 s5 是最重要的变量,并且通常它会导致预测发生较大的正向或负向变化。但是,是 s5 的大值导致正向变化,而小值导致负向变化吗?还是反之亦然,或者更复杂的情况?如果我们使用颜色来表示特征的大小,那么这将变得显而易见
[3]:
shap.summary_plot(
shap_values[:1000, :],
X.iloc[:1000, :],
plot_type="layered_violin",
color="coolwarm",
)
在这里,红色代表变量的大值,蓝色代表小值。因此,很明显 s5 的大值确实会增加预测,反之亦然。您还可以看到其他变量(如 s6)相当均匀地分布,这表明虽然它们总体上仍然重要,但它们的交互作用取决于其他变量。(毕竟,像 xgboost 这样的树模型的重点是捕获这些交互作用,所以我们不能期望在一个维度中看到一切!)
请注意,颜色的顺序并不重要:每个小提琴实际上是由多个 (
layered_violin_max_num_bins) 单独平滑的形状堆叠在一起组成的,其中每个形状对应于特征的某个百分位数(例如,s5 值的 5-10% 百分位数)。这些形状始终先绘制小值(因此最接近 x 轴),最后绘制大值(因此在“边缘”上),这就是为什么在这种情况下您总是看到红色在边缘,蓝色在中间。(当然,您可以使用不同的颜色映射来切换此顺序,但重点是红色在内/蓝色在外的顺序没有固有的含义。)
如果您愿意,还可以尝试其他选项。最值得注意的是上面提到的 layered_violin_max_num_bins。这还有一个额外的效果,如果特征的唯一值少于 layered_violin_max_num_bins,那么我们不是将每个部分划分为百分位数(上面的 5-10%),而是使每个部分代表一个特定值。例如,由于 sex 只有两个值,这里蓝色将表示男性(或女性?),红色表示女性(或男性?)。
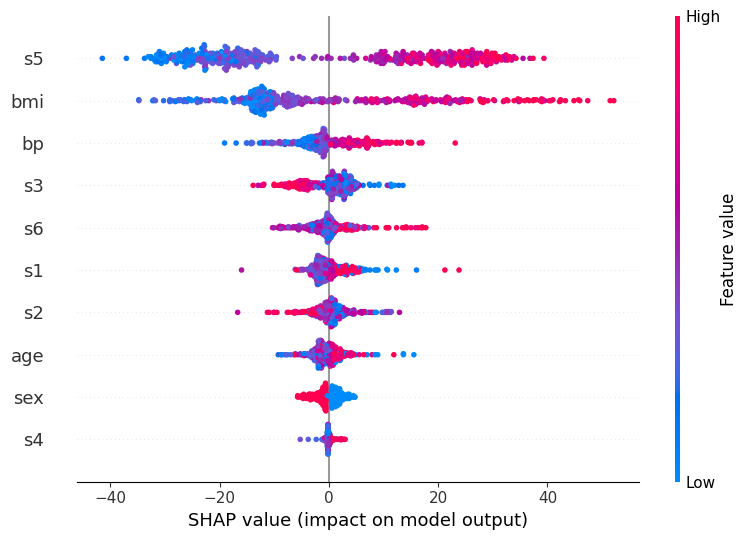
点图
点图将散点图与密度估计相结合,通过让点在不适合时堆积起来。这种方法的优点是它不会将任何东西隐藏在核平滑之后,因此您可以看到数据的精确表示。
[4]:
shap.summary_plot(shap_values[:1000, :], X.iloc[:1000, :])
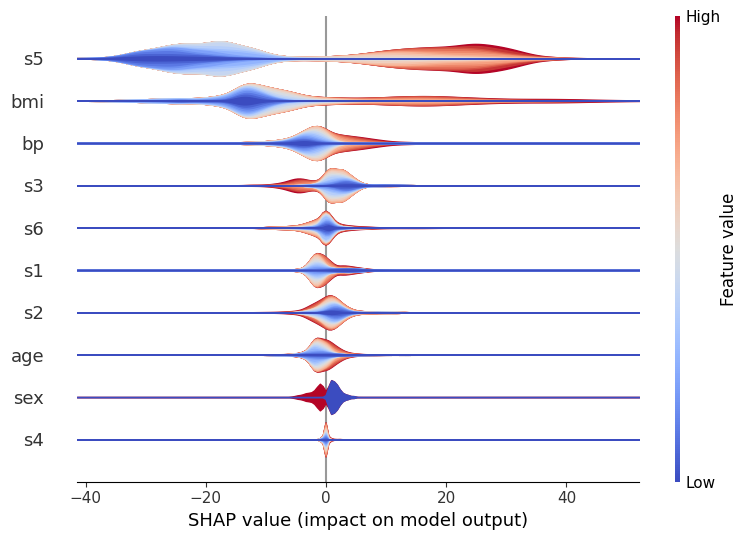
小提琴图
这些是标准小提琴图,但异常值绘制为点。与仅从几个点估计的核密度相比,这提供了更准确的异常值密度表示。颜色表示该位置的平均特征值,因此红色区域高特征值占主导地位,而蓝色区域低特征值占主导地位。
[5]:
shap.summary_plot(shap_values[:1000, :], X.iloc[:1000, :], plot_type="violin")