解释简单的 OR 函数
本笔记本电脑检查了使用 SHAP 值解释 OR 函数的外观。 通过此示例,我们了解更改背景分布如何影响从 TreeExplainer 获得的解释。
它基于一个简单的示例,其中包含两个特征 is_young 和 is_female,大致受泰坦尼克号生存数据集的启发,其中妇女和儿童在疏散期间获得优先权,因此更有可能生存。 在这个模拟示例中,这种效果被发挥到极致,所有儿童和妇女都幸存下来,而没有成年男子幸存。
[1]:
import numpy as np
import pandas as pd
import xgboost
from IPython.display import display
import shap
rng = np.random.default_rng(42)
创建遵循 OR 函数的数据集
[2]:
N = 40_000
M = 2
# randomly create binary features for `is_young` and `is_female`
X = (rng.standard_normal(size=(N, 2)) > 0) * 1
X = pd.DataFrame(X, columns=["is_young", "is_female"])
# force the first sample to be a young boy
X.loc[0, :] = [1, 0]
display(X.head(3))
# you survive (y=1) only if you are young or female
y = ((X.loc[:, "is_young"] + X.loc[:, "is_female"]).to_numpy() > 0) * 1
| is_young | is_female | |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 1 | 1 |
| 2 | 0 | 0 |
训练 XGBoost 模型来模拟此 OR 函数
[3]:
model = xgboost.XGBRegressor(n_estimators=100, learning_rate=0.1, random_state=3)
model.fit(X, y)
model.predict(X)
[3]:
array([9.9998671e-01, 9.9998671e-01, 1.3295135e-05, ..., 9.9998671e-01,
9.9998671e-01, 9.9998671e-01], dtype=float32)
解释年轻男孩的预测
使用训练集作为背景分布
请注意,在下面的示例解释中,is_young = True 具有正值(意味着它增加了模型输出,从而增加了生存预测),而 is_female = False 具有负值(意味着它减少了模型输出)。 虽然有人可能会争辩说 is_female = False 应该没有影响,因为我们已经知道这个人是年轻人,但 SHAP 值考虑了即使在我们不一定知道其他特征时,特征所产生的影响,这就是为什么 is_female = False 仍然对预测产生负面影响。
[4]:
explainer = shap.TreeExplainer(model, X, feature_perturbation="interventional")
explanation = explainer(X.loc[[0], :])
# for the young boy:
expected_value = explanation.base_values[0]
shap_values = explanation.values[0]
print(f"explainer.expected_value: {expected_value:.4f}")
print(f"SHAP values for (is_young = True, is_female = False): {shap_values.round(4)}")
print("model output:", (expected_value + shap_values.sum()).round(4))
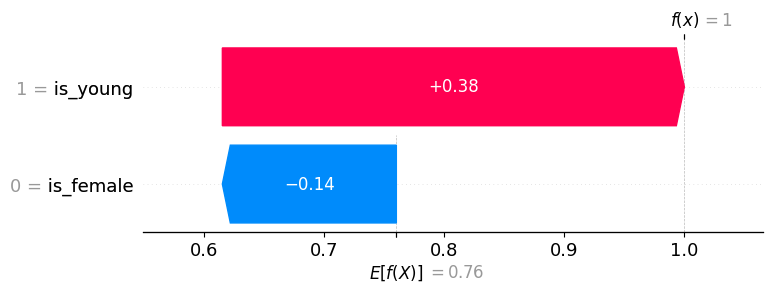
explainer.expected_value: 0.7600
SHAP values for (is_young = True, is_female = False): [ 0.385 -0.145]
model output: 1.0
与上面相同的信息,但可视化为瀑布图
[5]:
# waterfall plot for the young boy (background distribution => training set)
shap.plots.waterfall(explanation[0])
仅使用负例作为背景分布
第二个解释示例的目的是演示使用不同的背景分布如何改变输入特征之间信用分配。 发生这种情况是因为我们现在将特征的重要性与死者(成年男子)进行比较。 年轻男孩与死者唯一不同的是男孩年轻,因此所有功劳都归功于 is_young = True 特征。
这突出了当使用明确定义的背景组时,解释通常更清晰。 在这种情况下,它将解释从“此样本与典型的样本有何不同”更改为“此样本与死者有何不同”(换句话说,你为什么活着?)。
[6]:
explainer = shap.TreeExplainer(
model,
X.loc[y == 0, :], # background distribution => non-survival
feature_perturbation="interventional",
)
explanation = explainer(X.loc[[0], :])
# for the young boy:
expected_value = explanation.base_values[0]
shap_values = explanation.values[0]
print(f"explainer.expected_value: {expected_value:.4f}")
print(f"SHAP values for (is_young = True, is_female = False): {shap_values.round(4)}")
print("model output:", (expected_value + shap_values.sum()).round(4))
explainer.expected_value: 0.0000
SHAP values for (is_young = True, is_female = False): [1. 0.]
model output: 1.0
[7]:
# waterfall plot for the young boy (background distribution => non-survival)
shap.plots.waterfall(explanation[0])
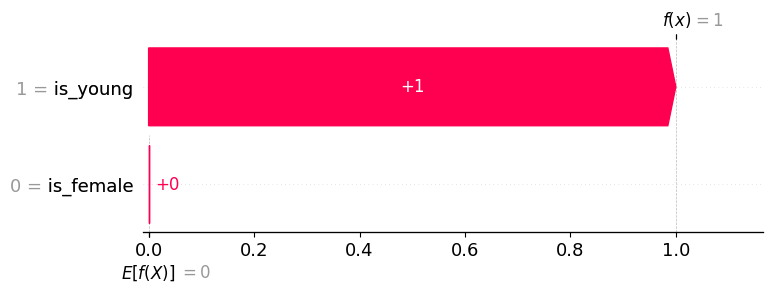
仅使用正例作为背景分布
我们也可以仅使用正例作为我们的背景分布,并且由于模型的预期输出(在我们的背景分布下)与年轻男孩的当前输出之间的差异为零,因此 SHAP 值的总和也将为零。
[8]:
explainer = shap.TreeExplainer(
model,
X.loc[y == 1, :], # background distribution => survival
feature_perturbation="interventional",
)
explanation = explainer(X.loc[[0], :])
# for the young boy:
expected_value = explanation.base_values[0]
shap_values = explanation.values[0]
print(f"explainer.expected_value: {expected_value:.4f}")
print(f"SHAP values for (is_young = True, is_female = False): {shap_values.round(4)}")
print("model output:", (expected_value + shap_values.sum()).round(4))
explainer.expected_value: 1.0000
SHAP values for (is_young = True, is_female = False): [ 0.14 -0.14]
model output: 1.0
[9]:
# waterfall plot for the young boy (background distribution => survival)
shap.plots.waterfall(explanation[0])
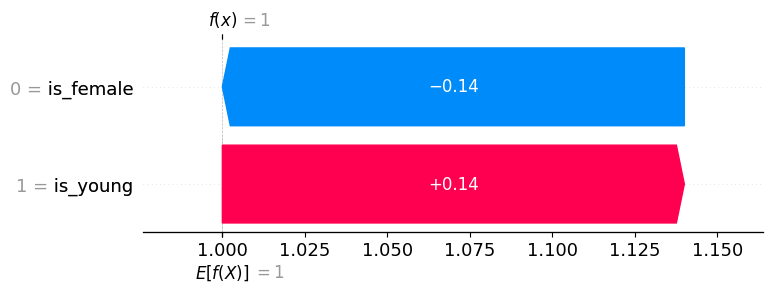
使用年轻女性作为背景分布
如果我们将样本与年轻女性进行比较,那么除了成年男性 (data=(0, 0)) 之外,没有任何特征重要,其中两个特征都被赋予了他们死亡的同等信用(正如人们可能凭直觉预期的那样)。
[10]:
explainer = shap.TreeExplainer(
model,
np.ones((1, M)), # background distribution => all young women
feature_perturbation="interventional",
)
explanation = explainer(X.head(3))
print("Feature data:")
display(explanation.data)
print()
print("SHAP values:")
display(explanation.values.round(4))
Feature data:
array([[1, 0],
[1, 1],
[0, 0]])
SHAP values:
array([[ 0. , -0. ],
[ 0. , 0. ],
[-0.5, -0.5]])